 |
Techniques for Reducing the Overhead of Run-time Parallelization
Techniques for Reducing the Overhead of Run-time Parallelization
Description
- To reduce the number of marks for memory references during speculative execution.
- Speculate about the data structures and reference patterns of the loop and customize the shape and size of the shadow structure. Based on the static reference patterns, we can choose proper shadow structures to minimize the memory overhead and and execution time.
- Same address type based aggregation - By utilizing the dominance relationship and the control dependence graph (CDG), we can eliminate redundant marks by combining marks based upon some rules. Two examples of the rules are illustrated in the picture. By traversing the CDG, loop invariant predicates will enable extracting an inspector loop.
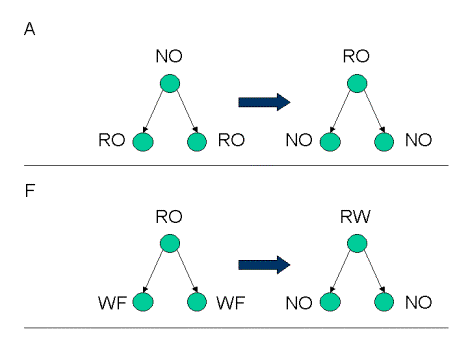
Aggregation Rules
- Grouping of related references - If references on different addresses always appear together or under the same condition, we call them related references. This optimization will try to separate references found in the loop into groups, which is a set of related references of the same access type (ReadOnly, WriteFirst, etc.). Also, we only mark one address for each group. Then, the grouping process finds a minimum number of disjoint sets of references having different subscripts. This optimization can reduce both the number of marking instructions and the size of shadow structure dramatically.
This is the algorithm for grouping:
Procedure: Grouping
Input: Statement N;
Predicate C;
Output: Groups return_groups;
Local: Groups branch_groups;
Branch branch;
Statement node;
Predicate path_condition;
return_groups = CompGroups ( N, C )
if ( N.succ_entries > 0 )
for (branch in N.succ)
Initialize ( branch_groups )
path_condition = C & branch_predicate
for ( node in B.succ )
branch_groups = branch_groups UNION Grouping ( node, path_condition )
end
return_groups = return_groups INTERSECTION branch_groups
end
return return_groups
endif
In order to benefit more from reducing the redundant marks, we studied sparse applications which introduced the following problems for the original LRPD test whose shadow structures are conformable arrays:
- The dimension of the array under test is much larger than the number of distinct elements referenced by loop.
- Use of shadow arrays can be very expensive.
- Need a compact shadow structure.
For the case study, we classified sparse accesses across iterations into three categories:
- Case A - Represent the references as a triplet.
- Case B - Represent the references as an array (conformable to the number of references).
- Case C - Represent the references using a hash table.

Example Sparse Access Patterns
Since we used compressed shadow structures, the dependence analysis at run-time is slightly different from the LRPD test (which used conformable shadow arrays). This procedure was implemented and in our run-time parallelization library.
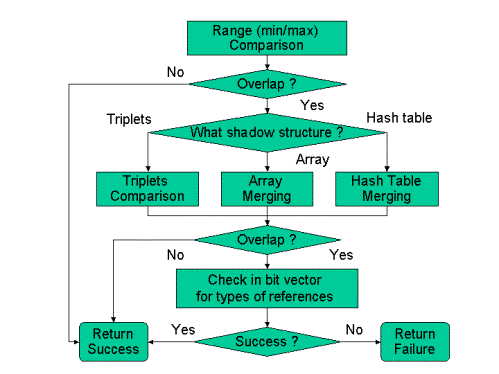
Run-Time Analysis Decision Tree
Experimental Results
The following table shows the performance improvement from reducing the redundant marks.
| Program: Loop | Marking Point Reduction % | Speedup Ratio |
|
|---|---|---|---|
| Static | Dynamic | ||
| SPICE 2G6: BJT | 91.3% | 83.88% | 1.461 |
| P3M: PP_do1100 | 50% | 40.57% | 1.538 |
| OCEAN: ftrvmt_do9109 | 50% | 50% | 1.209 |
| TFFT2: cfftz_do#1 | 55% | 68.75% | 1.686 |
Speedup Ratio = Execution Time of Loop w/out grouping / (... w/grouping)
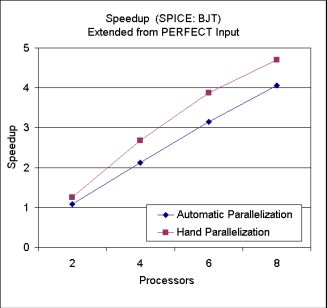
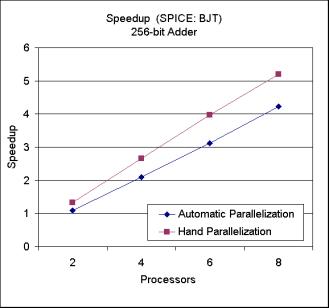
By using linked-list shadow structures, we have obtained good performance for the BJT loop in SPICE 2G6.
 |
 |
| Speedup for Extended PERFECT Input |
Speedup for 256-bit Adder |
Run-time Parallelization Optimization Techniques, Hao Yu, Lawrence Rauchwerger, In Wkshp. on Lang. and Comp.
for Par. Comp. (LCPC), San Diego, CA, Aug 1999.
Proceedings(ps, pdf, abstract)
Techniques for Reducing the Overhead of Run-time Parallelization, Hao Yu, Lawrence Rauchwerger, In Int. Conf. Compiler Construction (CC), pp. 232, Berlin, Germany, Mar 2000.
Proceedings(ps, pdf, abstract)
Presentations
Techniques for Reducing the Overhead of Run-time
Parallelization,
the 9th Int. Conference on Compiler Construction (CC'00), March 2000,
Berlin, Germany.
by Lawrence Rauchwerger