 |
|
||||||||||
SummarySmart Applications are composed of high level software components defined in STAPL, representing algorithms that have may several implementations and/or implementations which have parameters to tune their behaviour. Common examples include sorting (insertion sort, quicksort, mergesort, etc.) and minimum spanning tree computation (Kruskal's and Prim's algorithms). FAST aims to automate the selection and tuning decision, in an effort maximize performance by taking into account the execution environment and input sensitivities of the component invocation. 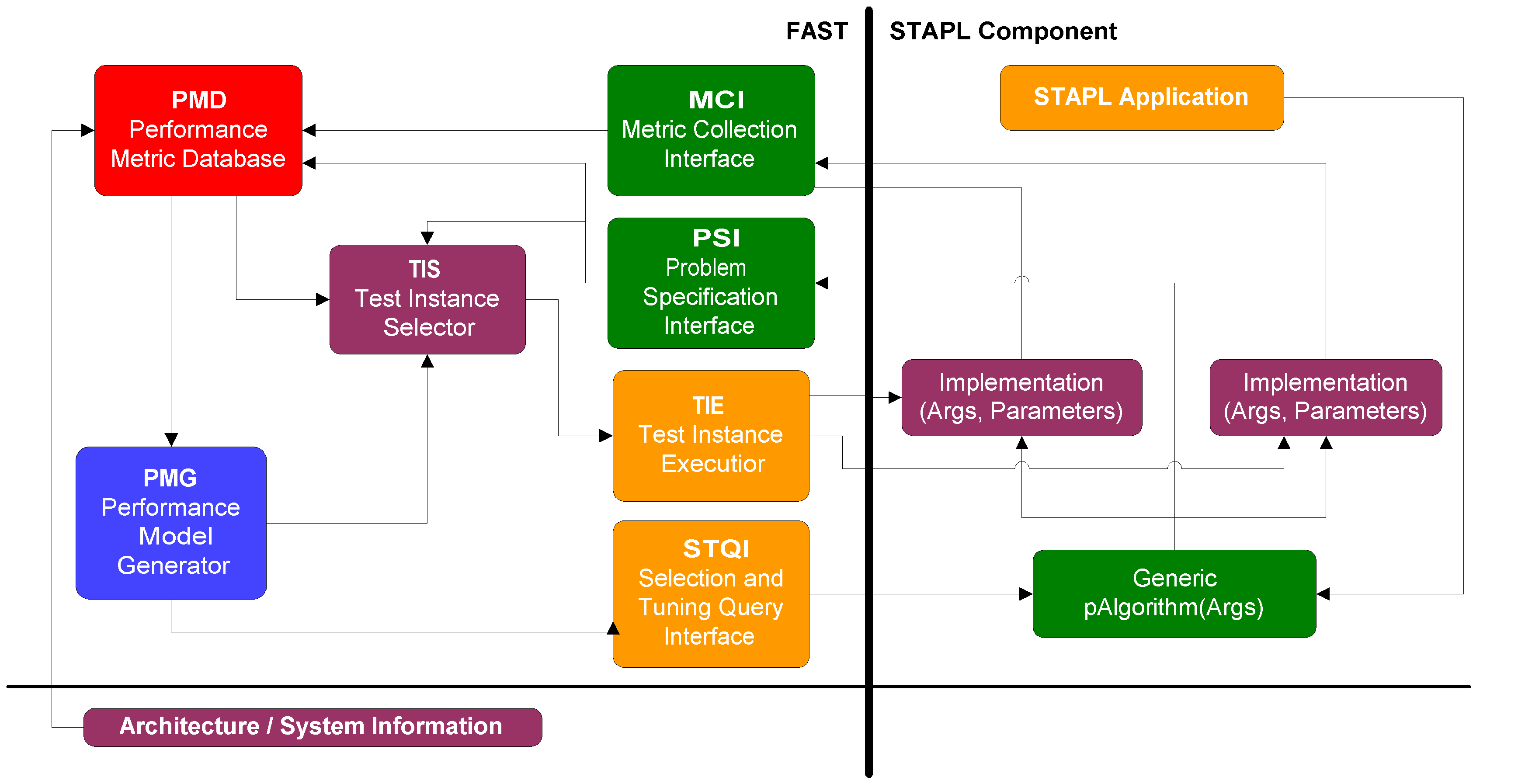
In a parallel and distributed setting, the situation becomes even more complex due to the wide variety of system architectures - and performance can even vary significantly for different sizes (e.g., number of processing elements) of a given architecture. These factors make it difficult for even an experienced programmer to determine which algorithm should be used in a given situation, and, perhaps more importantly, make it very difficult to write portable programs that perform well on multiple platforms or for varying input data sizes and types. Ideally, in such cases the programmer should only specify the operation desired (e.g., sort) and the decision of which algorithm to use should be made later, possibly even at run-time, once the environment and input characteristics are known. Our approach in FAST is to employ empirically based models that are created using training instances of the given selection problem. These instances are found by searching the problem instance space, dimensioned by attributes that are expected to effect performance. This search is done intelligently, guided by available architectural information, previously explored problem instances, and optional guidance provided by the programmer of STAPL components employing FAST. The search begins with an optional benchmarking phase performed during the installation of STAPL and continues with the consideration of instances executed during actual program runs. These dynamically updated models are made available generic components in STAPL to query as needed. Experimental Results
We have used our selection framework for parallel sorting, parallel multiplication, and parallel
reduction operations. Here we briefly show results for sorting. More extensive results
of all three algorithms are presented in the papers listed below. For sorting, we considered
three implementations: Radix Sort, Column Sort, and Sample Sort. Furthermore, we looked
at three different platforms:
Altix - an 128 processor SGI Altix 3700, with two 1.3Ghz Intel Itanium
4GB RAM and two processors per board, each with 3MB of L3 cache.
Its hypercube interconnect implements hardware DSM with CC-NUMA.
Cluster - an 1152 node Linux cluster located at Lawrence Livermore National
Laboratory. Each node has two 2.4Ghz Pentium 4 Xeon processors
each with a 512KB L2 cache and 4GB of memory. The Quadrics interconnect
uses a fat tree topology.
SMPCluster - a 68 node IBM cluster located at Lawrence Livermore National Laboratory.
Each node has sixteen 375Mhz POWER 3 Nighthawk-2 processors, each with an
8MB L2 cache and 16GB of memory. The interconnect is an internal IBM SP
multistage switch network.
Below is are the error rates for our sorting selection model on the three platforms. In all three cases, a decision tree learner (based on the ID3 algorithm) was employed. Given sufficient instances to learn from, accuracy ranged from 94% to 98% on the systems.
Here is a sample model generated by the learner for the Altix. Note that for this machine, processor count and a measure of presortedness (normalized distance) suffice to discriminate when to use each of the candidate algorithms.
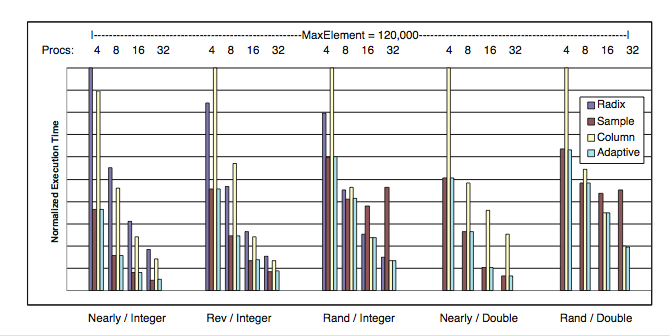
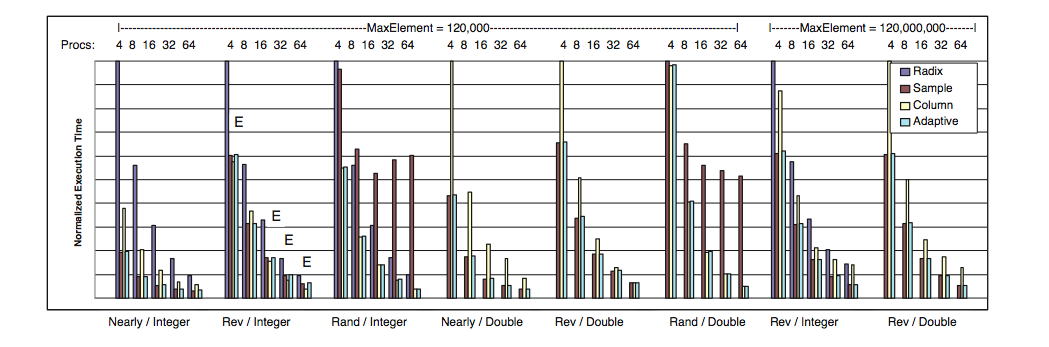
To validate the models on these platforms, we tested their accuracy on a set of problem instances not provided in the training phase. Specifically, we considered input sizes of 80M and 120M elements for both integer and doubles. The accuracy of the adaptive algorithm on the validation set was 100% on the SGI Altix and 93.3% on the Linux Cluster. For the cluster, the average relative performance penalty of mispredictions was 25.4% of the optimal algorithm. The two figures below show representative inputs from the validation testing on the SGI Altix and Linux Cluster. Each set of bars shows the performance of our adaptive algorithm and of the three base algorithms. Execution times for each category have been normalized by the maximum time from that category. Algorithm mispredictions (selecting the wrong algorithm), are denoted by ``E.''
|


Publications
A Framework for Adaptive Algorithm Selection in STAPL, Nathan Thomas, Gabriel Tanase, Olga Tkachyshyn, Jack Perdue, Nancy M. Amato, Lawrence Rauchwerger, In Proc. ACM SIGPLAN Symp.
Prin. Prac. Par. Prog. (PPOPP), pp. 277-288, Chicago, Illinois, Jun 2005.
Proceedings(ps, pdf, abstract)
An Adaptive Algorithm Selection Framework, Hao Yu, Dongmin Zhang, Lawrence Rauchwerger, In Proc. IEEE Int.Conf. on Parallel Architectures and Compilation Techniques (PACT), Antibes Juan-les-Pins, France, Sep 2004.
Proceedings(ps, pdf, abstract)
An Adaptive Algorithm Selection Framework, Hao Yu, Dongmin Zhang, Francis Dang, Lawrence Rauchwerger, Technical Report, TR04-002, Parasol Laboratory, Department of Computer Science, Texas A&M University, Mar 2004.
Technical Report(ps, pdf, abstract)
Adaptive Parallel Sorting in the STAPL library, Steven Saunders, Nathan Thomas, Nancy Amato, Lawrence Rauchwerger, Technical Report, TR01-005, Department of Computer Science and Engineering, Texas A&M University, Nov 2001.
Technical Report(abstract)
Run-time Parallelization Optimization Techniques, Hao Yu, Lawrence Rauchwerger, In Wkshp. on Lang. and Comp.
for Par. Comp. (LCPC), San Diego, CA, Aug 1999.
Proceedings(ps, pdf, abstract)