Introduction
There is a growing need to accurately simulate physical systems
whose evolutions depend on the transport of subatomic particles.
It has long been recognized that the huge computational demands of
the transport problem mean that practical solution times will be
obtained only by the efficient utilization of parallel processing.
For example, since estimates place the time devoted to particle
transport in multi-physics simulations at 50-80% of total execution time,
parallelizing deterministic particle transport calculations is an
important problem in many applications targeted by the DOE's
Accelerated Strategic Computing Initiative (ASCI). One common approach
to deterministic particle transport calculations is the discrete-ordinates
method, whose most time consuming step is the transport sweep which involves
multiple sweeps through the spatial grid, one for each direction of particle travel.
The efficient parallel implementation of the transport sweeps is the key
to parallelizing the discrete-ordinates method.
Contribution
Our key contribution to this field is a new general model that can
be used to compare the running times of transport sweeps on three-dimensional
orthogonal grids for various mappings of the grid cells to processors.
Our model, which includes machine-dependent parameters such as
computation cost and communication latency, can be used to analyze
and compare the effects of various spatial decompositions on the
running time of the transport sweep. Insight obtained from the model
yields two significant contributions to the theory of optimal transport
sweeps on orthogonal grids.
First, our model provides a theoretical basis which explains why, and
under what circumstances, the column decomposition of the current
standard KBA algorithm is superior to the `balanced' decomposition
obtained by classic domain decomposition techniques.
Second, our model enables us to identify a new decomposition, which we call
Hybrid, that proves to be almost as good as and sometimes
better than the current standard KBA method.
During each iteration, an ordered traversal through the spatial grid is
performed for each direction of particle travel.
A sweep of the grid begins at one of the eight corners,
depending on the direction desired. On an arbitrary grid, there may be as
many unique sweep orderings as there are directions. However,
for the orthogonal grids considered in this work, there are only eight
unique sweep orderings, one for each octant of directions. That is, if all
directions in a given octant are processed together, then eight distinct
traversals of the spatial grid must be performed in each iteration. The
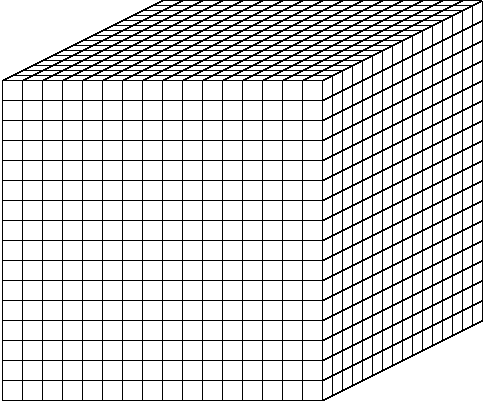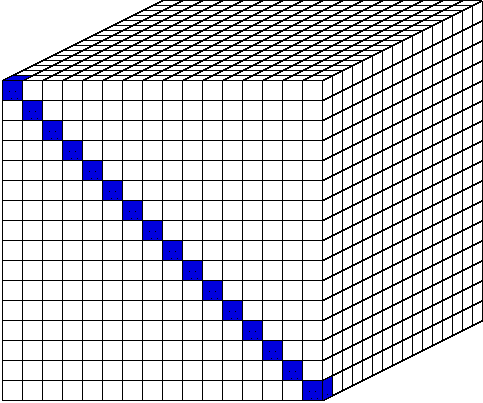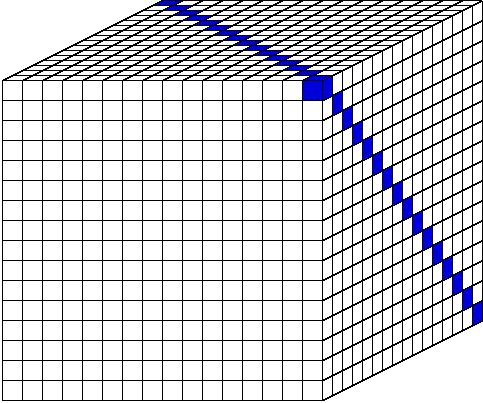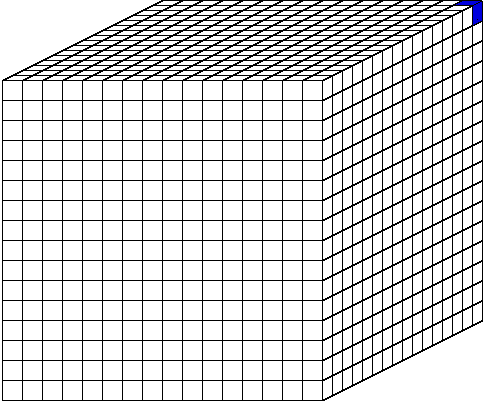
sweep for a given octant progresses from its starting corner across the
grid to the opposite corner following a diagonal trajectory.
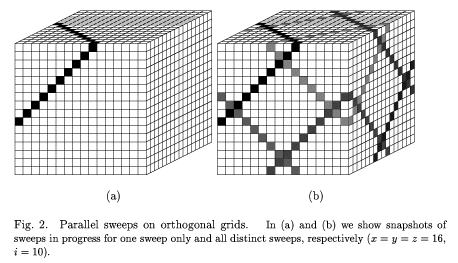
The constraining factor is that every
cell behind a diagonal plane must be calculated before any cell ahead of
the diagonal plane can be calculated. To simultaneously process all
directions, there is one sweep plane for each octant of
directions. It would appear that this
inherently sequential nature of the sweep would seriously inhibit any
parallel implementation of the basic sweep algorithm. However, while the
progress of the diagonal sweep plane is sequential, every cell inside the
sweep plane is independent of all other cells in the same plane. Therefore,
all cells in a sweep plane may be processed in parallel. Furthermore, the
sweeps for each direction are independent and can be processed in parallel.
The key factor determining the parallel efficiency of the sweeps is the
mapping of the spatial domain onto the processors, that is, the assignment
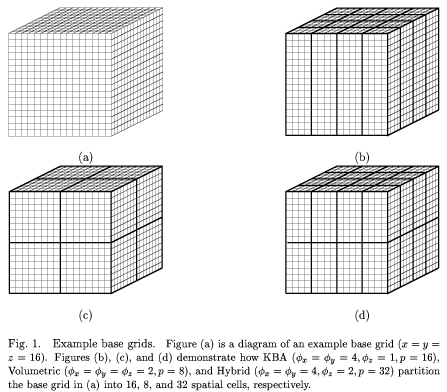
of the spatial cells to the processors. In this thesis, we develop a model
that can be used to analyze transport sweeps on regular orthogonal grids for
any `regular' mapping of the grid cells to processors. While the theory is
general, our analysis will concentrate on three different methods for
performing this decomposition: the column decomposition of the KBA
(which is the current standard), a Volumetric method which uses a `balanced'
decomposition (obtained by classic domain decomposition techniques), and then a
Hybrid approach that combines aspects of the first two methods. We have
selected these three decompositions since they represent the two extreme cases
(the KBA's columns vs. the Volumetric's balanced sub-domains) and an intermediate
case (Hybrid).
Inter-processor communication will be required to move data from an
`upstream' cell on one processor to an adjacent `downstream' cell on another
processor, where which cells are upstream and downstream depends on the
sweep direction. During a sweep, each processor will calculate one or more
contiguous planes of cells in its partition before it processes the next set of cells
in its partition and before the next processor can process its adjacent set of cells.
It is important to note that the time to process one block of cells is highly
dependent on the partitioning method being used.
Theoretical Model
The total time required by the sweep algorithm, or completion time, T,
is the collective sum of all computation and communication required on the critical path.
The computation time is the summation of the computation required for each individual step.
The communication time is the summation of all outstanding communication
required to perform the transport sweep. This assumption limits communication time to
cross-processor communication that cannot be pipelined. Combining these assumptions
gives us an expression for the completion time, T (we find it useful to normalize the equation
by dividing through by the grind time, omega).
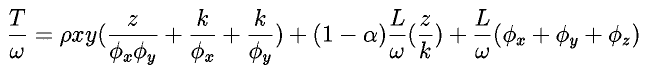
where,
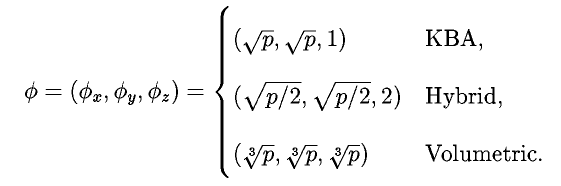

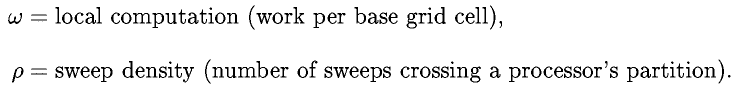

The performance of any method can be tuned using the block size parameter,
k. Specifically, we want to choose a k such that the completion time
is minimized. The optimal value of k can easily be found by
minimizing the model equation with respect to k.
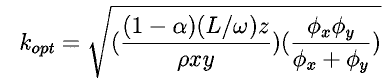
The key contribution of this thesis is a new general model which can
be used to predict the running time of parallel sweeps on orthogonal
grids for any regular mapping of the grid cells to processors. In
particular, our model accounts for machine-dependent parameters such as
computation and communication/latency costs (assumed constant for all grid
cells) and is parameterized by the number of processors,
the dimensions of the underlying spatial transport grid, and
the dimensions of the coarse grid processor
overlay (which determines the dimensions of the sub-domain assigned to
each processor). Thus, our model can be used to analyze and compare the
effects of various spatial decompositions on the running time of the transport
sweep.
Insight obtained from the model yields the following contributions to the
theory of optimal transport sweeps on orthogonal grids.
- Our model provides a theoretical basis that explains why, and
under what circumstances, the column decomposition of the current
standard KBA algorithm is superior to the
`balanced' decomposition' obtained by classic domain decomposition
techniques.
- Our model enables us to identify a new decomposition that proves
to be almost as good as and often better than the current standard
KBA method. We call this new decomposition the Hybrid method
because it incorporates positive aspects of both the KBA and the
balanced decomposition.
- A more minor (but still potentially valuable) contribution of our
work is a theoretical expression for the optimal `block size' parameter
in the sweep method (the number of cells a processor should process
before communicating).
The methods we have analyzed represent a family of algorithms for
three dimensional sweeps. Given an input grid and a parallel computer
system (i.e., number of processors and estimates of computation and
communication costs for each grid cell), one can select the best method
for the given configuration. Furthermore, one can minimize the completion
time by selecting an optimal block size. Future work on this subject will
involve correctly accounting for restarts in the execution of the transport
sweep.
Provably Optimal Parallel Transport Sweeps on Regular Grids, W Hawkins, Timmie Smith, Michael Adams, Lawrence Rauchwerger, Nancy Amato, Marvin Adams, Teresa Bailey, Robert Falgout, In Proc. Int. Conf. on
Math. Meth. and Supercomp. for Nuc. App., Idaho, May 2013.
Proceedings(pdf, abstract)
Efficient Massively Parallel Transport Sweeps, W Hawkins, Timmie Smith, Michael Adams, Lawrence Rauchwerger, Nancy Amato, Marvin Adams, Trans. Amer. Nucl. Soc., 107(1):477-481, Nov 2012.
Journal(pdf)
Finding Strongly Connected Components in Parallel in Particle Transport Sweeps, William McLendon, Bruce Hendrickson, Steve Plimpton, Lawrence Rauchwerger, In Proc. ACM Symp. Par. Alg.
Arch. (SPAA), pp. 328-329, Crete, Greece, Jul 2001.
Proceedings(ps, pdf, abstract)
A General Performance Model for Parallel Sweeps on Orthogonal Grids for Particle Transport Calculations, Mark M. Mathis, Masters Thesis, Department of Computer Science and Engineering, Texas A&M University, Dec 2000.
Masters Thesis(ps, pdf, abstract)
A General Performance Model for Parallel Sweeps on Orthogonal Grids for Particle Transport Calculations, Mark M. Mathis, Nancy M. Amato, Marvin Adams, In Proc. ACM Int. Conf.
Supercomputing (ICS), pp. 255-263, Santa Fe, NM, May 2000. Also, Technical Report, TR00-004, Parasol Laboratory, Department of Computer Science, Texas A&M University, Dec 1999.
Proceedings(ps, pdf, abstract) Technical Report(ps, pdf, abstract)
Supported by NSF, DOE (ASCI ASAP Level 2 and 3 Programs)
Project Alumni:Michael Adams,W Hawkins,Bruce Hendrickson,Mark M. Mathis,William McLendon,Steve Plimpton