Robust Online Belief Space Planning
Robust Online Belief Space Planning in Changing Environments:
Application to Physical Mobile Robots
This section describes how to address the physical issues that arise when trying to conduct motion planning under uncertainty with FIRM.
Method overview
Proposed
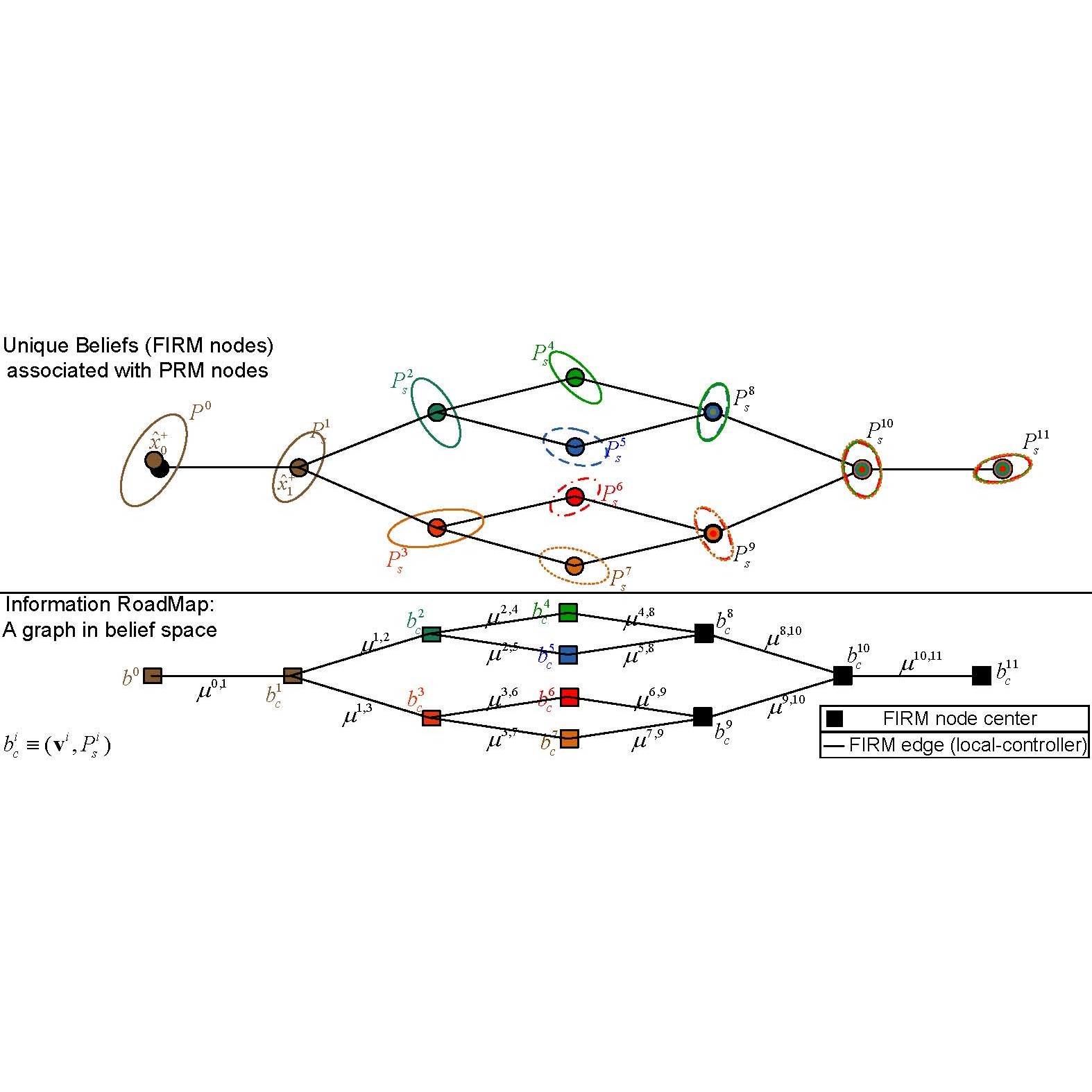
Robust motion planning under uncertainty with FIRM is done with a dynamic replanning scheme.
FIRM replans using receding horizon control in the belief space until the goal is found.
- FIRM solves an optimization problem to find the optimal policy from a given node to the goal node.
- Firm finds and applies the control which corresponds to the optimal policy at its given belief state<\li>
- Observe the new observation
- Compute the new belief
Notably, the optimal policy is recomputed at each iteration.
Lazy Feedback Evaluation in Changing Environments
To address changing environments, an online planner can use lazy evaluation.
The basic idea is that at every node the robot re-evaluates
only the next edge that it needs to take or a limited set of edges in the vicinity of the robot.
By re-evaluation, we mean re-compute the collision probabilities along the edges.
If needed, the dynamic programming problem is re-solved and a new feedback tree is computed.
Handling the kidnapped robot problem
To address this problem, a robot must be able to detect a kidnapped situation, localize itself, and replan.
These issues can be handled respectively as follows:
- A robot running firm can have an internal record of the relative ranges and bearings of the robot to landsmarks, noticing it has been kidnapped if a threshold is met
- The robot enters an information gathering mode with a large covariance matrix
- The robot need only traverse to the nearest node, since the FIRM graph is a multi-query graph