Our technique for computing protein folding pathways and protein motions is based on the successful probabilistic roadmap (PRM) method for robotics motion planning. We were inspired to apply PRMs to protein folding based on our sccess in applying it to paper folding. The figure below demonstrates the parallelism between paper folding and protein folding.
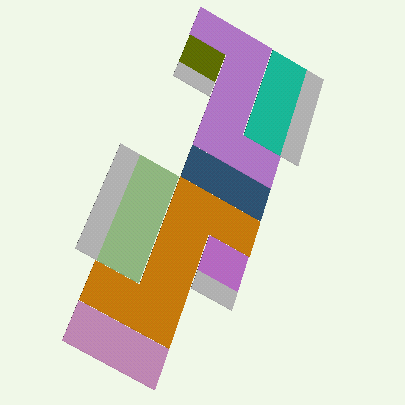
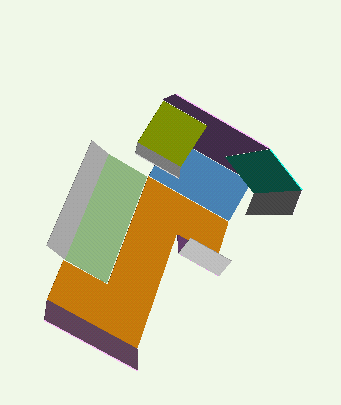
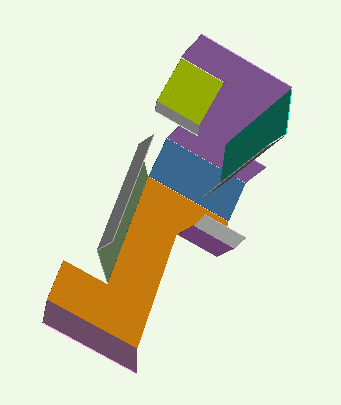
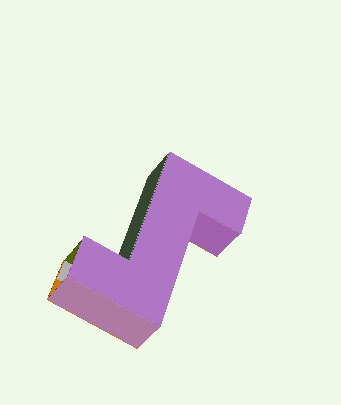
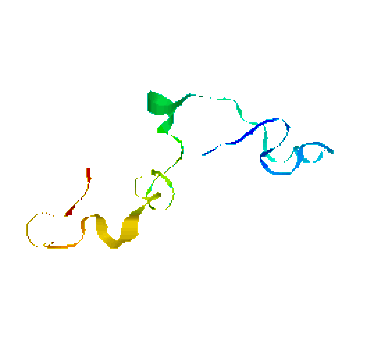

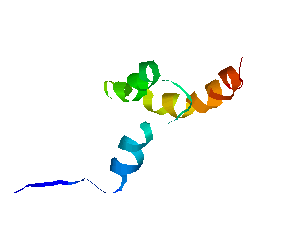
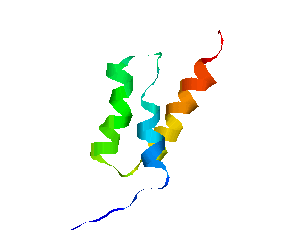
We have obtained promising results for several small proteins (about 60-100 amino acids), and we have validated our pathways by comparing their secondary structure formation order with known experimental results, examining folding rate, and studying population kinetics. A major feature of our technique is that it produces many folding pathways in just a few hours on a desktop PC. These pathways provide global information about the protein's energy landscape.
| Protein G |
Protein L |
NuG1 |
NuG2 |

|
|

|

|
Native 3D structures of proteins G, L, NuG1, and NuG2. Mutated residues in NuG1 and NuG2 are indicated in wireframe.
All four proteins are composed of an alpha-helix (green) and two beta-hairpin 1 (orange) and hairpin 2 (blue). Native state out-exchnage experiments, pulse labeling/competition experiments, and phi-value analysis indicate that hairpin 1 forms first in protein L and hairpin 2 forms first in protein G. Protein G was then mutated by submitting a few residues in hairpin 2 to decrease its relaitve stability. Phi-value analysis indicates that the mutations switch the hairpin formation order from the wildtype to that of the protein L. We were able to successfully replicate these results with out technique. For each protein, we analyzed hundreds of folding pathways. The following table shows out simulation results:
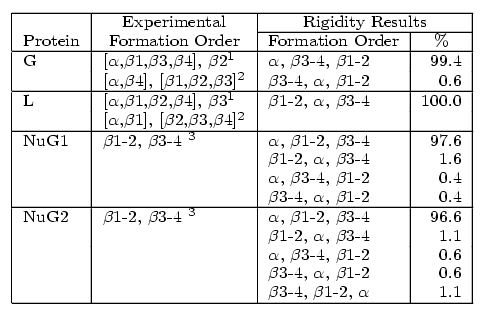
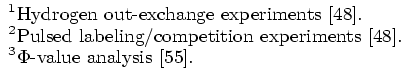 Comparison of secondary structure formation order for proteins G, L, NuG1, and NuG2 with experimental results.
Comparison of secondary structure formation order for proteins G, L, NuG1, and NuG2 with experimental results.
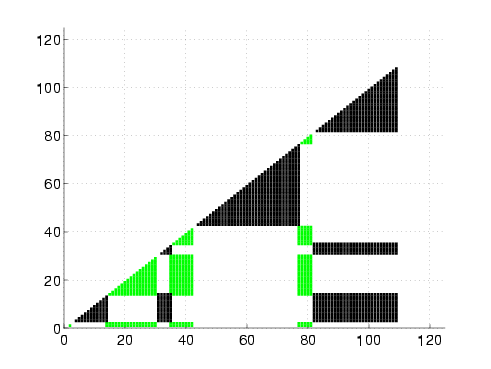
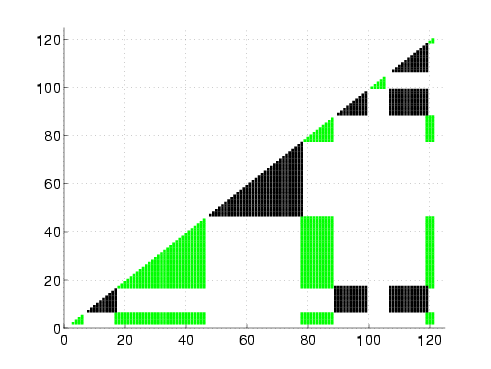
In addtion to detecting the correct folding behavior of each protein, our rigidity-based technique can also help explain the stability shift in NuG1 and NuG2 from the wildtype. Consider their native state rigidity maps:
|
Protein G |
Protein L |
NuG1 |
NuG2 |
|
|
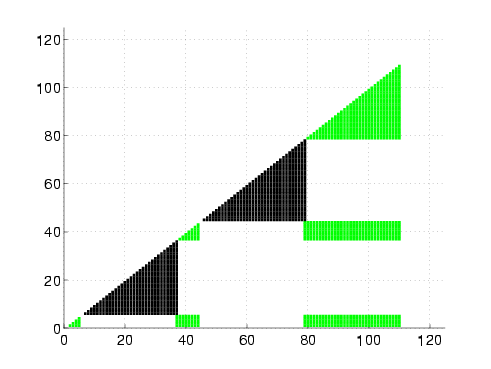
|
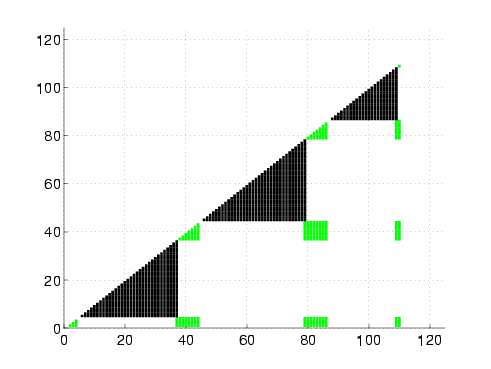
|
Rigidity maps of the native structure for proteins G, L, NuG1, and NuG2.
A rigidity map is similar to a contact map except residues pairs are marked according to their rigidity relationship: black if they are in the same rigid component, green if they are in the same dependently flexible set, and white otherwise. In all four proteins, the central alpha-helix remains completely rigid, as expected. We also increased rigidity from our protein G to NuG1 and NuG2 in hairpin 1 as suggested by experiment. For the other regions, the rigidity maps show more similarity between the mutated forms of protein G and protein L than with protein G, reflecting the similarity/difference in folding behaviors.
Our roadmaps provide an approxiamte view of a protein's folding landscape. In our recent work, we have explored various methodologies for studying the kinetics of protein folding in these approximate models. Our two methodologies, map-based Master Equation (MME) and map-based Monte Carlo (MMC), allow us to study two important features of protein folding kinetics: relative folding rate and population kinetics. While master equation calculation and Monte Carlo simulation have been performed on protein models before, their computational cost have prohibitied them from being used for large protein models. An important benefit of our map-based apporximation approach is that it enables us to study the kinetics of much larger proteins than can be handled by traditional master equation solution or Monte Carlo simulation.
We can use the MME approach to study relative folding rate as extracted from our roadmaps. For this study, we looked at Protein G and its variants NuG1 and NuG2. Experimental studies have shown that these two mutants folds 100 times faster than protein G. We applied the MME approach to study the relative folding rates of these proteins.
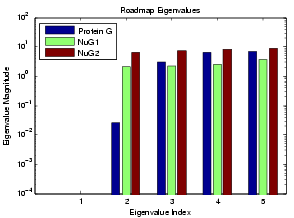
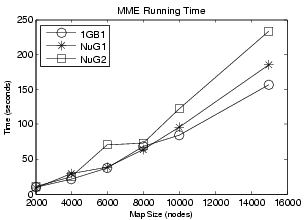
In the figure above, the simulated folding rates are shown for Protein G and its mutants NuG1 and NuG2. The plotted eigenvalues were calculated using MME. Note that the smalled non-zero eigenvalues correspond to the folding rate (index 2). Our simulations show that Protein G folds much slower than its mutants NuG1 and NuG2. This is what has been seen in lab experiments.
Also shown above is the performance of MME roadmaps ranging in size from 2000 to 15000 nodes. The running time of MME scales linearly with roadmap size (i.e. the size of the landscape model).
| |
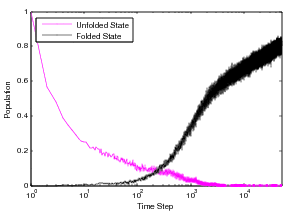
Population Kinetics |
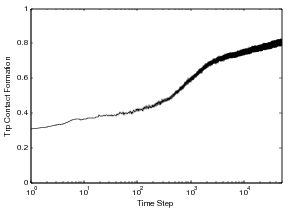
Tryptophan Contact Formation |
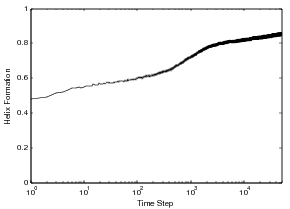
Helix Formation |
|
Protein ACBP
|
|
|
|
Displayed in the figure above is the 86 residue all alpha protein, Acyl-coenzyme A Binding Protein (ACBP), we have studied through the MMC technique. This protein has five helices and two tryptophans in the core of the protein. The folding of ACBP has been studied in the lab thourgh tryptophan fluorescence, and it has been shown that it has a fast, two-state folder. From our MMC kinetics, we see that ACBP exhibits a property similar to otehr all alpha proteins we have studied: continual formation of helix contacts and reaching the native state after teh formation of many helix contacts. Also, since ACBP has two tryptophans in the core of the protein, we see a quick increase in the formation of these contacts around the same time we see the native state beginning to be populated, around time step 100. This could correspond to the packing of the structure and the formation of long-range interactions in the core of the protein. We also show this protein has similar kinetics to other all alpha-proteins and other lab experiments on alpha proteins. Through the technique we have been able to study population kinetics for proteins of various lengths and mixed structures.
We have also used our roadmaps, or approxiamte landscape models, to simulate relative hydrogen exchange rates and infer the folding core. The folding core is the set of residues that are the first to form structure during folding and the last to lose structure during denaturation. One of the most prevalent experimental methods to infer the folding core is hydrogen exchange. It measures the rate at which residues exchange their hydrogens for Deuterium during either folding or unfolding.
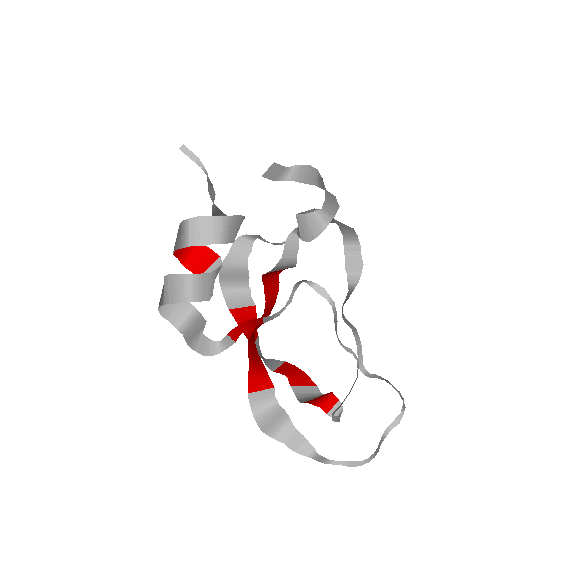
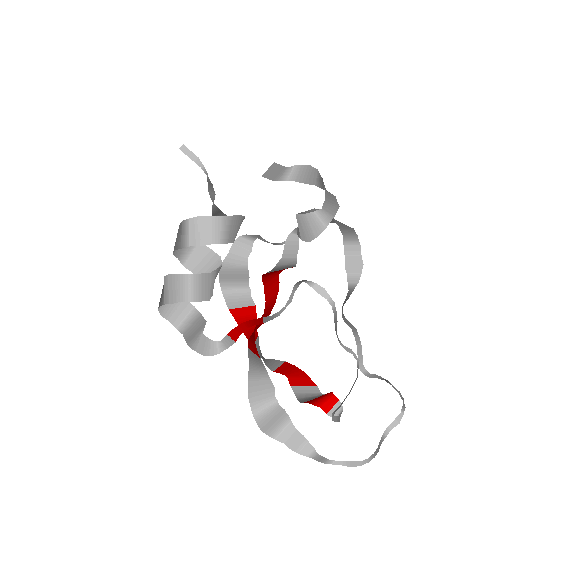
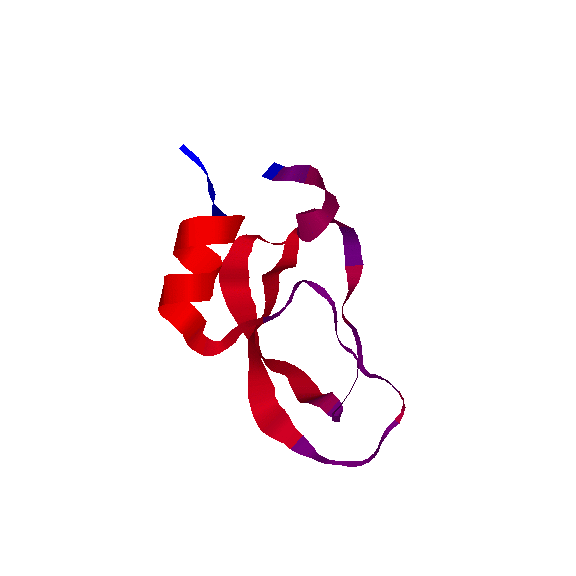
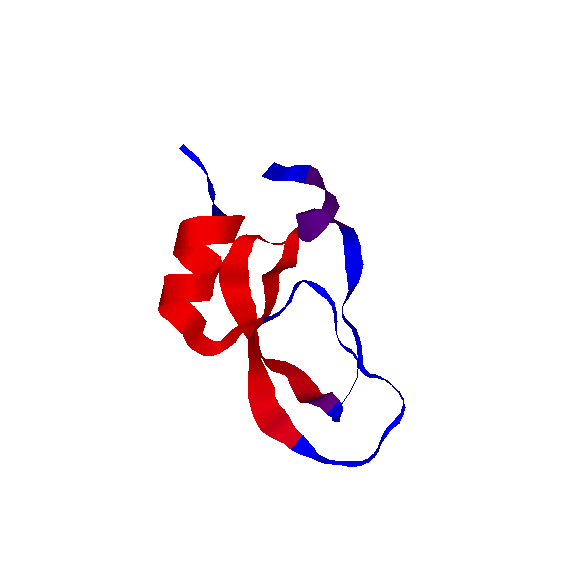
We use rigidity analysis to examine the folding pathways on our roadmaps (typically extracted by MMC) and compute an approxiamte exchange rate for each residue. We developed two approaches for approximating exchange: one looks at the indiviual residue's rigidity/flexibility and one looks at the formation of mutually rigid, non-local subsequences. We found good correlation between the residues identified experimentally as part of the folding core and residues we identify with slow exchange rates:
|
|
|
|
|
|
Continuous Labeling EX [Hilton78]
|
Continuous Labeling EX [Richarz79]
|
Pulse Labeling EX [Roder86]
|
Simulated Relative EX
(by rigidity/flexibility)
|
Simulated Relative EX
(by mutually rigid subsequences)
|
Robotic motion planning algorithms, such as Rapidly Exploring Random Trees (RRTs), have been successful in simulating
protein folding pathways. We developed a novel variant, multi-directional Rapidly Exploring Random Graph (mRRG),
specifically tailored for proteins.
Unlike traditional RRGs which only expand a parent conformation in a single direction, our strategy expands the parent
conformation in multiple directions to generate new samples. Resulting samples are connected to the parent conformation
and its nearest neighbors. By leveraging multiple directions, mRRG can model the protein motion landscape with reduced
computational time compared to several other robotics-based methods for mall to moderate-sized proteins.
Our results on several proteins agree with experimental hydrogen out-exchange, pulse-labeling, and phi-value analysis.
We also demonstrated that mRRG covers the conformation space better as compared to the other computational methods.
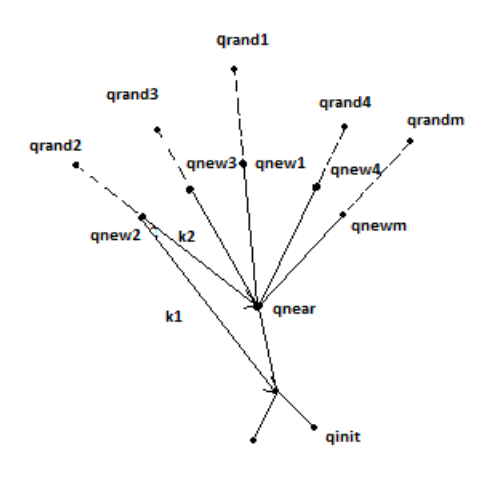
An example of mRRG. Instead of a single sample, m random samples are generated to guide expansion.
Predicting protein structures and simulating protein folding motions are two of the most important
problems in computational biology today. Modern folding simulation methods rely on a scoring function,
which attempts to distinguish the native structure (the most energetically stable 3D structure) from one
or more non-native structures.
Decoy databases are collections of non-native structures that are widely used to test and verify these scoring functions.
We present a method to evaluate and improve the quality of decoy databases by adding novel structures and/or removing redundant structures.
We test our approach on decoy databases of varying size and type and show significant improvement across a variety of metrics.
Most improvement comes from the addition of novel structures indicating that our improved databases have more informative structures
that are more likely to fool scoring functions. This work can aid the development and testing of better scoring functions,
which in turn, will improve the quality of protein folding simulations.
We apply our methods to existing decoy sets and show that our algorithms are able to generate sets with lower energies and more diverse structures
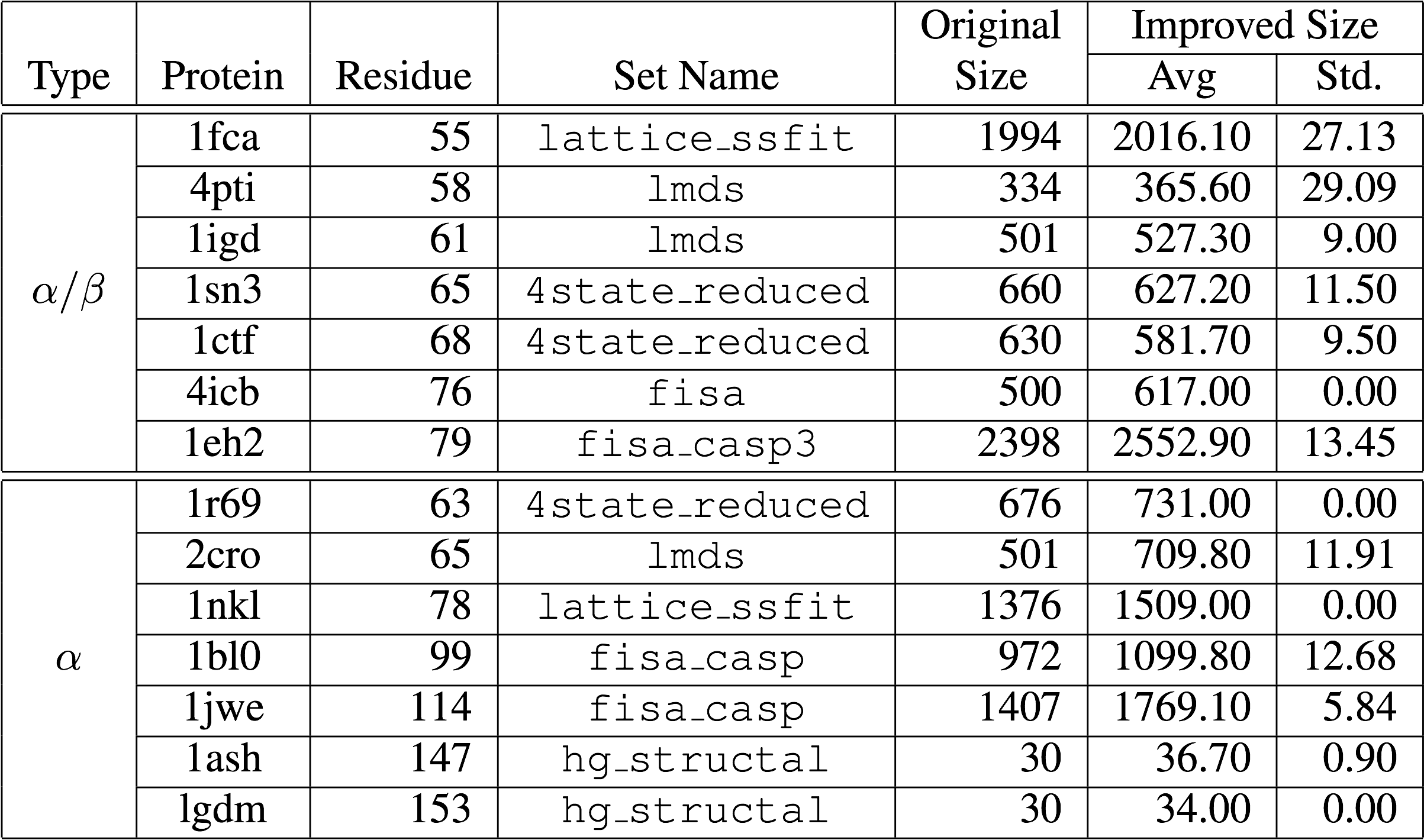
that are more likely to fool scoring functions of protein folding algorithms. All decoy sets were obtained from the Decoys 'R' Us database and are listed in the following table.
Because our methods improve existing decoy sets, we first develop strategies for analyzing the quality of decoy sets. We present several quantitative metrics to compare decoy sets and describe how their values are calculated in the experiments.
Z-Score - The z-score (or standard score) indicates the number of standard deviations between the native structure energy adn teh average energy of a decoy set.
MinDist - The minimum distance metric measures the average minimum distance from each decoy structure to any other decoy structure in the set.
Improvement - Given an original decoy set and an improved decoy set, the improvement score returns the change in z-score per sample between the two sets.
There are two main phases in the improvement of decoy sets. First, samples are generated on the protein's energy landscape. Second, in the decoy selection phase, some structures are chosen from the original set D to be removed and some are chosen from the sample set S to be added. The original decoy set D and the sample set S can be broken down into four subsets:
- redundant decoy structures DD from D,
- viable decoy structures DV from D,
- redundant sampled structures SD from S, and
- viable sampled structures SV from S.
The following figure shows the relationship between these four subsets.
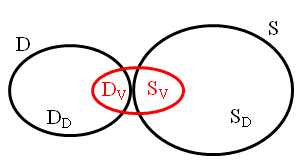
The next three figures summarize the resulting z-score, improvement score, and minimum distance value for each protein studied. For each metric, we show the contribution from each operation (removing redundant decoys (DV), adding new samples (D U SV) and from their combination (DV U SV).
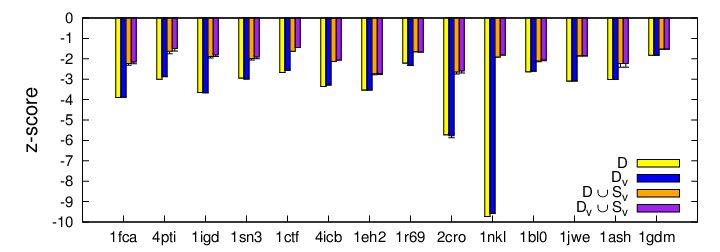
When the z-score approached zero, the native structure energy is harder to distinguish among the energies of the other structures in the set. For every protein in this figure, the z-scores of D and DV are very similar. Thus, simply removing structures does not greatly impact the z-score. However, once we add new structures from our sampling approach (D U SV), the z-score drops drastically with comparable z-scores to the final set (DV U SV). Therefore, the main contributors to z-score improvement are the structures generated by our sampling approach.
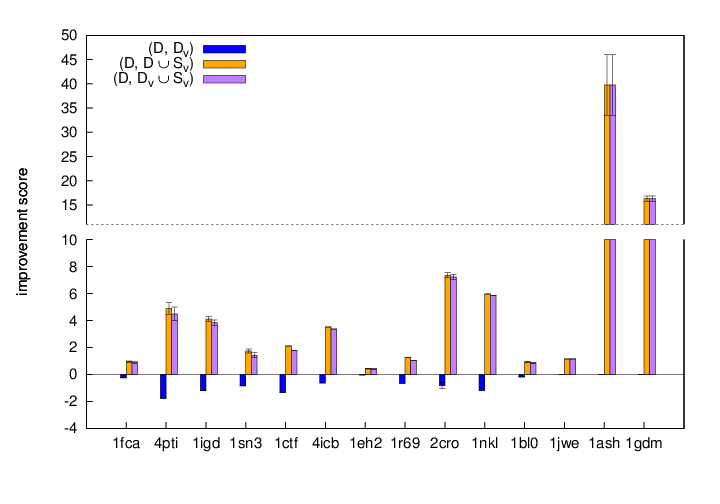
Recall that the improvement score shows the change in z-score per sample between two sets. A higher value indicates that the change (either structure addtion, removal, or both) has a greater impact on the z-score. This figure displays the improvement scores across all test proteins. We again see that adding structures provide a decoy set with better quality than simply removing redundant structures. Proteins 1ash and 1gdm with the smallest original sets show the largest improvement scores.
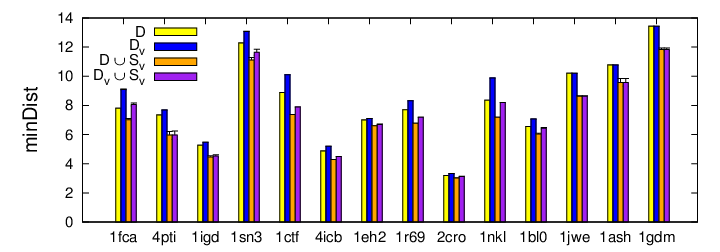
The last metric we examine is the minimum distance between neighboring structures which indicates how varied the structures. A larger distance signifies greater structural diversity and implies a greater ability to fool different scoring functions. This figure shows how this metric changes for each operation. As expected, when decoys are removed (D), the minimum distance increases, and when V adding decoys (D U SV), the minimum distance decreases. For all protein studied, the final decoy set (DV U SV) has smaller minimum distance than the original set (D) yielding a set with greater diversity.
Related Publications
Adaptive Local Learning in Sampling Based Motion Planning for Protein Folding, Chinwe Ekenna and Shawna Thomas and Nancy M. Amato, BMC Syst Biol, Special Issue from the 2015 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Vol: 10, Issue: 49, pp. 165-179, Aug 2016. DOI: 10.1186/s12918-016-0297-9
Keywords: Computational Biology, Protein Folding
Links : [Published]
BibTex
@article{ekenna-bmcsb-2016
, author = "Chinwe Ekenna and Shawna Thomas and Nancy M. Amato"
, title = "Adaptive Local Learning in Sampling Based Motion Planning for Protein Folding"
, journal = "BMC Syst Biol, Special Issue from IEEE International Conference on Bioinformatics and Biomedicine (BIBM)"
, volume = "10"
, number = "49"
, pages = "165--179"
, year = "2016"
, month = "August"
, doi = "10.1186/s12918-016-0297-9"
}
Abstract
Background
Simulating protein folding motions is an important problem in computational biology. Motion planning algorithms, such as Probabilistic Roadmap Methods, have been successful in modeling the folding landscape. Probabilistic Roadmap Methods and variants contain several phases (i.e., sampling, connection, and path extraction). Most of the time is spent in the connection phase and selecting which variant to employ is a difficult task. Global machine learning has been applied to the connection phase but is inefficient in situations with varying topology, such as those typical of folding landscapes.
Results
We develop a local learning algorithm that exploits the past performance of methods within the neighborhood of the current connection attempts as a basis for learning. It is sensitive not only to different types of landscapes but also to differing regions in the landscape itself, removing the need to explicitly partition the landscape. We perform experiments on 23 proteins of varying secondary structure makeup with 52ÃÂÃÂÃÂâÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂ114 residues. We compare the success rate when using our methods and other methods. We demonstrate a clear need for learning (i.e., only learning methods were able to validate against all available experimental data) and show that local learning is superior to global learning producing, in many cases, significantly higher quality results than the other methods.
Conclusions
We present an algorithm that uses local learning to select appropriate connection methods in the context of roadmap construction for protein folding. Our method removes the burden of deciding which method to use, leverages the strengths of the individual input methods, and it is extendable to include other future connection methods.
Decoy Database Improvement for Protein Folding, Hsin-Yi (Cindy) Yeh, Aaron Lindsey, Chih-Peng Wu, Shawna Thomas, and Nancy M. Amato, Journal of Computational Biology, Vol: 22, Issue: 9, pp. 823-836, Sep 2015. DOI: 10.1089/cmb.2015.0116
Keywords: Computational Biology, Protein Folding
Links : [Published]
BibTex
@article{yeh-jcb-2015
, author = "Hsin-Yi Yeh and Aaron Lindsey and Chih-Peng Wu and Shawna Thomas and Nancy M. Amato"
, title ="Decoy Database Improvement for Protein Folding"
, journal = "Journal of Computational Biology"
, volume = "22"
, number = "9"
, year = "2015"
, pages = "823-836"
, doi = "10.1089/cmb.2015.0116"
}
Abstract
Predicting protein structures and simulating protein folding are two of the most important problems in computational biology today. Simulation methods rely on a scoring function to distinguish the native structure (the most energetically stable) from non-native structures. Decoy databases are collections of non-native structures used to test and verify these functions.
We present a method to evaluate and improve the quality of decoy databases by adding novel structures and removing redundant structures. We test our approach on 20 different decoy databases of varying size and type and show significant improvement across a variety of metrics. We also test our improved databases on two popular modern scoring functions and show that for most cases they contain a greater or equal number of native-like structures than the original databases, thereby producing a more rigorous database for testing scoring functions.
Rigidity Analysis for Protein Motion and Folding Core Identification, Shawna Thomas, Lydia Tapia, Chinwe Ekenna, Hsin-Yi (Cindy) Yeh, Nancy M. Amato, Association for the Advancement of Artificial Intelligence (AAAI) Workshop, Vol: WS-13-06, pp. 38-43, Bellevue, Washington, Jul 2013.
Keywords: Computational Biology, Protein Folding, Sampling-Based Motion Planning
Links : [Published]
BibTex
@inproceedings{thomas-aaaiW-2013
, author = "Shawna Thomas and Lydia Tapia and Chinwe Ekenna and Hsin-Yi (Cindy) Yeh and Nancy M. Amato "
, title = "Rigidity Analysis for Protein Motion and Folding Core Identification"
, booktitle = "AAAI Workshop on Artificial Intelligence and Robotics Methods in Computational Biology"
, volume = "WS-13-06"
, month = "July"
, address = "Bellevue, Washington, USA"
, pages = "38-43"
, year = "2013"
}
Abstract
Protein folding plays an essential role in protein function and stability. Despite the explosion in our knowledge of structural and functional data, our understanding of protein folding is still very limited. In addition, methods such as folding core identification are gaining importance with the increased desire to engineer proteins with particular functions and efficiencies. However, defining the folding core can be challenging for both experiment and simulation. In this work, we use rigidity analysis to effectively sample and model the protein's energy landscape and identify the folding core. Our results show that rigidity analysis improves the accuracy of our approximate landscape models and produces landscape models that capture the subtle folding differences between protein G and its mutants, NuG1 and NuG2. We then validate our folding core identification against known experimental data and compare to other simulation tools. In addition to correlating well with experiment, our method can suggest other components of structure that have not been identified as part of the core because they were not previously measured experimentally.
A Multi-Directional Rapidly Exploring Random Graph (mRRG) for Protein Folding, Shuvra Nath, Shawna Thomas, Chinwe Ekenna, Nancy M. Amato, Proc. ACM Conference on Bioinformatics, Computational Biology and Biomedicine (BCB), pp. 44-51, Orlando, FL, USA, Oct 2012. DOI: 10.1145/2382936.2382942
Keywords: Computational Biology, Protein Folding
Links : [Published]
BibTex
@inproceedings{nath-bcb-2012
, author = "Shuvra Nath and Shawna Thomas and Chinwe Ekenna and Nancy M. Amato"
, title = "A Multi-Directional Rapidly Exploring Random Graph (mRRG) for Protein Folding"
, booktitle = "ACM Conference on Bioinformatics, Computational Biology and Biomedicine (BCB)"
, pages = "44-51"
, location ="Orlando, FL, USA"
, month = "October"
, year = "2012"
, doi = "10.1145/2382936.2382942"
}
Abstract
Modeling large-scale protein motions, such as those involved in folding and binding interactions, is crucial to better understanding not only how proteins move and interact with other molecules but also how proteins misfold, thus causing many devastating diseases. Robotic motion planning algorithms, such as Rapidly Exploring Random Trees (RRTs), have been successful in simulating protein folding pathways. Here, we propose a new multi-directional Rapidly Exploring Random Graph (mRRG) specifically tailored for proteins.
Unlike traditional RRGs which only expand a parent conformation in a single direction, our strategy expands the parent conformation in multiple directions to generate new samples. Resulting samples are connected to the parent conformation and its nearest neighbors. By leveraging multiple directions, mRRG can model the protein motion landscape with reduced computational time compared to several other robotics-based methods for small to moderate-sized proteins. Our results on several proteins agree with experimental hydrogen out-exchange, pulse-labeling, and æ-value analysis. We also show that mRRG covers the conformation space better as compared to the other computation methods.
Tools for Simulating and Analyzing RNA Folding Kinetics, Xinyu Tang, Shawna Thomas, Lydia Tapia, Nancy M. Amato, In. Proc. International Conference on Research in Computational Molecular Biology, Oaklanda, California, USA, Apr 2007. DOI: 10.1007/978-3-540-71681-5_19
Keywords: Computational Biology, RNA, Sampling-Based Motion Planning
Links : [Published]
BibTex
@InProceedings{10.1007/978-3-540-71681-5_19,
author="Tang, Xinyu
and Thomas, Shawna
and Tapia, Lydia
and Amato, Nancy M.",
editor="Speed, Terry
and Huang, Haiyan",
title="Tools for Simulating and Analyzing RNA Folding Kinetics",
booktitle="Research in Computational Molecular Biology",
year="2007",
publisher="Springer Berlin Heidelberg",
address="Berlin, Heidelberg",
pages="268--282",
isbn="978-3-540-71681-5"
}
Abstract
It has recently been found that some RNA functions are determined by the actual folding kinetics and not just the RNAâÃÂÃÂs nucleotide sequence or its native structure. We present new computational tools for simulating and analyzing RNA folding kinetic metrics such as population kinetics, folding rates, and the folding of particular subsequences. Our method first builds an approximate representation (called a map) of the RNAâÃÂÃÂs folding energy landscape, and then uses specialized analysis techniques to extract folding kinetics from the map. We provide a new sampling strategy called Probabilistic Boltzmann Sampling (PBS) that enables us to approximate the folding landscape with much smaller maps, typically by several orders of magnitude. We also describe a new analysis technique, Map-based Monte Carlo (MMC) simulation, to stochastically extract folding pathways from the map. We demonstrate that our technique can be applied to large RNA (e.g., 200+ nucleotides), where representing the full landscape is infeasible, and that our tools provide results comparable to other simulation methods that work on complete energy landscapes. We present results showing that our approach computes the same relative functional rates as seen in experiments for the relative plasmid replication rates of ColE1 RNAII and its mutants, and for the relative gene expression rates of MS2 phage RNA and its mutants.
Parallel Protein Folding with STAPL, Shawna Thomas, Gabriel Tanase, Lucia K. Dale, Jose E. Moreira, Lawrence Rauchwerger, Nancy M. Amato, Concurrency and Computation: Practice and Experience, Vol: 17, Issue: 14, pp. 1643-1656, Dec 2005. DOI: https://doi.org/10.1002/cpe.950
Keywords: Parallel Planning, Protein Folding, STAPL
Links : [Published]
BibTex
@article{https://doi.org/10.1002/cpe.950,
author = {Thomas, Shawna and Tanase, Gabriel and Dale, Lucia K. and Moreira, Jose M. and Rauchwerger, Lawrence and Amato, Nancy M.},
title = {Parallel protein folding with STAPL},
journal = {Concurrency and Computation: Practice and Experience},
volume = {17},
number = {14},
pages = {1643-1656},
keywords = {protein folding, motion planning, parallel libraries, C++},
doi = {https://doi.org/10.1002/cpe.950},
url = {https://onlinelibrary.wiley.com/doi/abs/10.1002/cpe.950},
eprint = {https://onlinelibrary.wiley.com/doi/pdf/10.1002/cpe.950},
abstract = {Abstract The protein-folding problem is a study of how a protein dynamically folds to its so-called native state—an energetically stable, three-dimensional conformation. Understanding this process is of great practical importance since some devastating diseases such as Alzheimer's and bovine spongiform encephalopathy (Mad Cow) are associated with the misfolding of proteins. We have developed a new computational technique for studying protein folding that is based on probabilistic roadmap methods for motion planning. Our technique yields an approximate map of a protein's potential energy landscape that contains thousands of feasible folding pathways. We have validated our method against known experimental results. Other simulation techniques, such as molecular dynamics or Monte Carlo methods, require many orders of magnitude more time to produce a single, partial trajectory. In this paper we report on our experiences parallelizing our method using STAPL (Standard Template Adaptive Parallel Library) that is being developed in the Parasol Lab at Texas A\&M. An efficient parallel version will enable us to study larger proteins with increased accuracy. We demonstrate how STAPL enables portable efficiency across multiple platforms, ranging from small Linux clusters to massively parallel machines such as IBM's BlueGene/L, without user code modification. Copyright © 2005 John Wiley \& Sons, Ltd.},
year = {2005}
}
Abstract
The protein-folding problem is a study of how a protein dynamically folds to its so-called native state - an energetically stable, three-dimensional conformation. Understanding this process is of great practical importance since some devastating diseases such as Alzheimer's and bovine spongiform encephalopathy (Mad Cow) are associated with the misfolding of proteins. We have developed a new computational technique for studying protein folding that is based on probabilistic roadmap methods for motion planning. Our technique yields an approximate map of a protein's potential energy landscape that contains thousands of feasible folding pathways. We have validated our method against known experimental results. Other simulation techniques, such as molecular dynamics or Monte Carlo methods, require many orders of magnitude more time to produce a single, partial trajectory. In this paper we report on our experiences parallelizing our method using STAPL (Standard Template Adaptive Parallel Library) that is being developed in the Parasol Lab at Texas A&M. An efficient parallel version will enable us to study larger proteins with increased accuracy. We demonstrate how STAPL enables portable efficiency across multiple platforms, ranging from small Linux clusters to massively parallel machines such as IBM's BlueGene/L, without user code modification.
Protein Folding by Motion Planning, Shawna Thomas, Guang Song, Nancy M. Amato, Physical Biology, Vol: 2, Issue: 4, pp. S148-S155, Nov 2005. DOI: 10.1088/1478-3975/2/4/S09
Keywords: Protein Folding, Sampling-Based Motion Planning
Links : [Published]
BibTex
@article{Thomas_2005,
doi = {10.1088/1478-3975/2/4/s09},
url = {https://doi.org/10.1088%2F1478-3975%2F2%2F4%2Fs09},
year = 2005,
month = {nov},
publisher = {{IOP} Publishing},
volume = {2},
number = {4},
pages = {S148--S155},
author = {Shawna Thomas and Guang Song and Nancy M Amato},
title = {Protein folding by motion planning},
journal = {Physical Biology},
abstract = {We investigate a novel approach for studying protein folding that has evolved from robotics motion planning techniques called probabilistic roadmap methods (PRMs). Our focus is to study issues related to the folding process, such as the formation of secondary and tertiary structures, assuming we know the native fold. A feature of our PRM-based framework is that the large sets of folding pathways in the roadmaps it produces, in just a few hours on a desktop PC, provide global information about the protein\'s energy landscape. This is an advantage over other simulation methods such as molecular dynamics or Monte Carlo methods which require more computation and produce only a single trajectory in each run. In our initial studies, we obtained encouraging results for several small proteins. In this paper, we investigate more sophisticated techniques for analyzing the folding pathways in our roadmaps. In addition to more formally revalidating our previous results, we present a case study showing that our technique captures known folding differences between the structurally similar proteins G and L.}
}
Abstract
We investigate a novel approach for studying protein folding that has evolved from robotics motion planning techniques called probabilistic roadmap methods (PRMs). Our focus is to study issues related to the folding process, such as the formation of secondary and tertiary structures, assuming we know the native fold. A feature of our PRM-based framework is that the large sets of folding pathways in the roadmaps it produces, in just a few hours on a desktop PC, provide global information about the protein\'s energy landscape. This is an advantage over other simulation methods such as molecular dynamics or Monte Carlo methods which require more computation and produce only a single trajectory in each run. In our initial studies, we obtained encouraging results for several small proteins. In this paper, we investigate more sophisticated techniques for analyzing the folding pathways in our roadmaps. In addition to more formally revalidating our previous results, we present a case study showing that our technique captures known folding differences between the structurally similar proteins G and L.
Using Motion Planning to Map Protein Folding Landscapes and Analyze Folding Kinetics of Known Native Structures , Nancy M. Amato, Ken A. Dill, Guang Song, Journal of Computational Biology, Vol: 10, Issue: 3-4, pp. 239-255, Jul 2004. DOI: 10.1089/10665270360688002
Keywords: Computational Biology, Protein Folding, Sampling-Based Motion Planning
Links : [Published]
BibTex
@article{10.1089/10665270360688002,
author ={Nancy M. {Amato}, Ken {Dill}, Guang {Song}},
title ={Using Motion Planning to Map Protein Folding Landscapes and Analyze Folding Kinetics of Known Native Structures},
journal ={Journal of Computational Biology},
volume ={10},year ={2004},number ={3-4},pages ={239-255},
doi={10.1089/10665270360688002}
}
Abstract
We investigate a novel approach for studying the kinetics of protein folding. Our framework has evolved from robotics motion planning techniques called probabilistic roadmap methods (PRMs) that have been applied in many diverse fields with great success. In our previous work, we presented our PRM-based technique and obtained encouraging results studying protein folding pathways for several small proteins. In this paper, we describe how our motion planning framework can be used to study protein folding kinetics. In particular, we present a refined version of our PRM-based framework and describe how it can be used to produce potential energy landscapes, free energy landscapes, and many folding pathways all from a single roadmap which is computed in a few hours on a desktop PC. Results are presented for 14 proteins. Our ability to produce large sets of unrelated folding pathways may potentially provide crucial insight into some aspects of folding kinetics, such as proteins that exhibit both two-state and three-state kinetics that are not captured by other theoretical techniques.
Parallel Protein Folding with STAPL, Shawna Thomas, Nancy M. Amato, 18th International Parallel and Distributed Processing Symposium (IPDPS), pp. 189-, Santa Fe, NM, USA, Apr 2004. DOI: 10.1109/IPDPS.2004.1303204
Keywords: Parallel Planning, Protein Folding, STAPL
Links : [Published]
BibTex
@INPROCEEDINGS{1303204,
author={S. {Thomas} and N. M. {Amato}},
booktitle={18th International Parallel and Distributed Processing Symposium, 2004. Proceedings.},
title={Parallel protein folding with STAPL},
year={2004},
volume={},
number={},
pages={189-},
doi={10.1109/IPDPS.2004.1303204}}
Abstract
Summary form only given. The protein folding problem is to study how a protein dynamically folds to its so-called native state - an energetically stable, three-dimensional configuration. Understanding this process is of great practical importance since some devastating diseases such as Alzheimer\'s and bovine spongiform encephalopathy (Mad Cow) are associated with the misfolding of proteins. In our group, we have developed a new computational technique for studying protein folding that is based on probabilistic roadmap methods for motion planning. Our technique yields an approximate map of a protein\'s potential energy landscape that contains thousands of feasible folding pathways. We have validated our method against known experimental results. Other simulation techniques, such as molecular dynamics or Monte Carlo methods, require many orders of magnitude more time to produce a single, partial, trajectory. We report on our experiences parallelizing our method using STAPL (the standard template adaptive parallel library), that is being developed in the Parasol Lab at Texas A&M. An efficient parallel version enables us to study larger proteins with increased accuracy. We demonstrate how STAPL enables portable efficiency across multiple platforms without user code modification. We show performance gains on two systems: a dedicated Linux cluster and an extremely heterogeneous multiuser Linux cluster.
Using Motion Planning to Study RNA Folding Kinetics, Xinyu Tang, Bonnie Kirkpatrick, Shawna Thomas, Guang Song, Nancy M. Amato, In Proc. Int. Conf. Comput. Molecular Biology (RECOMB), pp. 252-261, Mar 2004. DOI: 10.1145/974614.974648
Keywords: Computational Biology, RNA, Sampling-Based Motion Planning
Links : [Published]
BibTex
@inproceedings{10.1145/974614.974648,
author = {Tang, Xinyu and Kirkpatrick, Bonnie and Thomas, Shawna and Song, Guang and Amato, Nancy M.},
title = {Using Motion Planning to Study RNA Folding Kinetics},
year = {2004},
isbn = {1581137559},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/974614.974648},
doi = {10.1145/974614.974648},
abstract = {We propose a novel, motion planning based approach to approximately map the energy landscape of an RNA molecule. Our method is based on the successful probabilistic roadmap motion planners that we have previously successfully applied to protein folding. The key advantage of our method is that it provides a sparse map that captures the main features of the landscape and which can be analyzed to compute folding kinetics. In this paper, we provide evidence that this approach is also well suited to RNA. We compute population kinetics and transition rates on our roadmaps using the master equation for a few moderately sized RNA and show that our results compare favorably with results of other existing methods.},
booktitle = {Proceedings of the Eighth Annual International Conference on Resaerch in Computational Molecular Biology},
pages = {252–261},
numpages = {10},
keywords = {motion planning, RNA, folding kinetics},
location = {San Diego, California, USA},
series = {RECOMB \'04}
}
Abstract
We propose a novel, motion planning based approach to approximately map the energy landscape of an RNA molecule. Our method is based on the successful probabilistic roadmap motion planners that we have previously successfully applied to protein folding. The key advantage of our method is that it provides a sparse map that captures the main features of the landscape and which can be analyzed to compute folding kinetics. In this paper, we provide evidence that this approach is also well suited to RNA. We compute population kinetics and transition rates on our roadmaps using the master equation for a few moderately sized RNA and show that our results compare favorably with results of other existing methods.
A Path Planning-based Study of Protein Folding With a Case Study of Hairpin Formation in Protein G and L, Guang Song, Shawna Thomas, Ken A. Dill, J. Martin Scholtz, Nancy M. Amato, In Proc. Pac. Symp. of Biocomputing (PSB), Vol: 8, pp. 240-251, Lihue, Hawaii, Jan 2003.
Keywords: Computational Biology, Protein Folding, Sampling-Based Motion Planning
Links : [Published]
BibTex
@INPROCEEDINGS{Song_2003,
author={Guang {Song}, Shawna {Thomas}, Ken A. {Dill}, J. Martin {Scholtz}, Nancy M. {Amato}},
booktitle={In Proc. Pac. Symp. of Biocomputing (PSB)},
title={A Path Planning-based Study of Protein Folding With a Case Study of Hairpin Formation in Protein G and L},
year={2003}, volume={8}, number={}, pages={240-251},
doi={}
}
Abstract
We investigate a novel approach for studying protein folding that has evolvedfrom robotics motion planning techniques calledprobabilistic roadmapmethods(prms). Our focus is to study issues related to the folding process, such as theformation of secondary and tertiary structure,assumingweknowthenativefold.A feature of ourprm-based framework is that the large sets of folding pathwaysin the roadmaps it produces, in a few hours on a desktop PC, provide globalinformation about the proteinÃÂâÃÂÃÂÃÂÃÂs energy landscape. This is an advantage over othersimulation methods such as molecular dynamics or Monte Carlo methods whichrequire more computation and produce only a single trajectory in each run. Inour initial studies, we obtained encouraging results for several small proteins. Inthis paper, we investigate more sophisticated techniques for analyzing the foldingpathways in our roadmaps. In addition to more formally revalidating our previousresults, we present a case study showing our technique captures known foldingdifferences between the structurally similar proteins G and L.
A motion planning approach to folding: from paper craft to protein folding, Guang Song, Nancy M. Amato, In Proc. IEEE Int. Conf. Robot. Autom. (ICRA), Vol: 1, pp. 948-953, Seoul, Korea, May 2001. DOI: 10.1109/ROBOT.2001.932672
Keywords: Path Planning, Protein Folding, Sampling-Based Motion Planning
Links : [Published]
BibTex
@INPROCEEDINGS{932672,
author={ {Guang Song} and N. M. {Amato}},
booktitle={Proceedings 2001 ICRA. IEEE International Conference on Robotics and Automation (Cat. No.01CH37164)}, title={A motion planning approach to folding: from paper craft to protein folding},
year={2001},
volume={1},
number={},
pages={948-953 vol.1},
doi={10.1109/ROBOT.2001.932672}}
Abstract
We present a framework for studying folding problems from a motion planning perspective. Modeling foldable objects as tree-like multi-link objects allows one to apply motion planning techniques to folding problems. An important feature of this approach is that it not only allows one to study foldability questions, such as, can an object be folded (or unfolded) into another object, but also provides one with another tool for investigating the dynamic folding process itself. The framework proposed here has application to traditional motion planning areas such as automation and animation, and presents a novel approach for studying protein folding pathways. Preliminary experimental results with traditional paper crafts (e.g., box folding) and small proteins (approximately 60 residues) are quite encouraging.
