Scheduling Sweeps for Particle Transport Calculations
In this work, we consider
the relationship between task scheduling and deterministic mesh sweeps
that arise in particle-transport computations. In particular, we argue
that the efficient parallelization of such computations is most accurately
viewed as a generalization of the traditional task scheduling problem and
not as an application for domain decomposition, as has been generally assumed
in the past. In fact, as we show, the transport problem represents an interesting
composite task-scheduling problem: given one set of tasks, and multiple
dependence graphs for these tasks (one for each distinguishable sweep direction),
find an assignment of tasks to processors that minimizes the time required
to process all such graphs. Within this context, we study and propose scheduling
algorithms that are suitable for the particular generalization of the scheduling
problem that arises in the context of transport sweeps.
ASCI scheduler is developed for the ASCI
project to optimize the Particle transport Calculations on parallel
systems, specificly for the scheduling of multiple dependence computation
graphs emerged from the ASCI project. The problem is classified into two
categories:
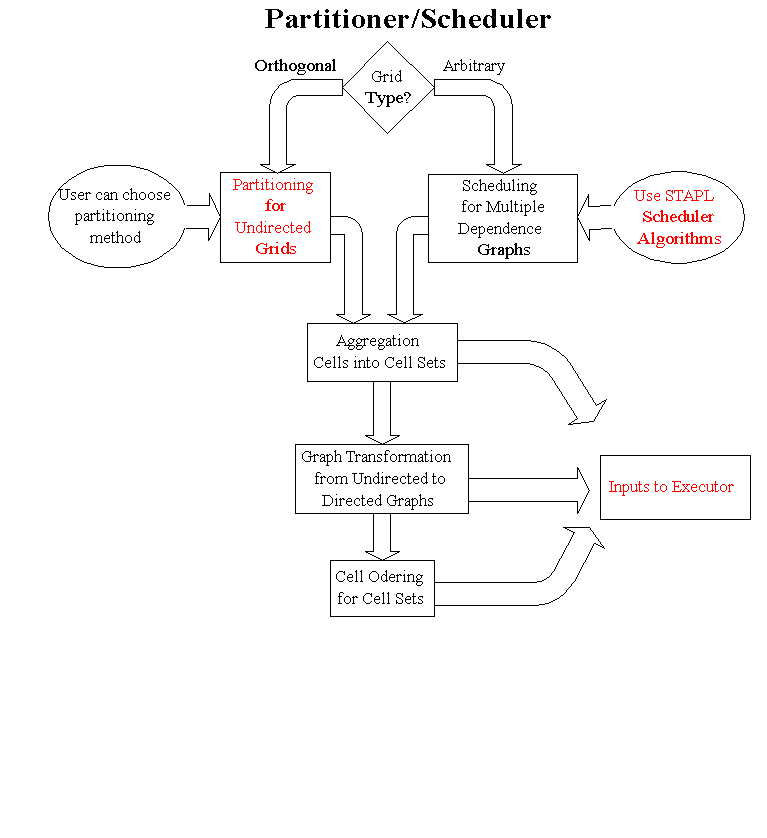
For general scheduling to apply to both orthogonal and unstructured grids,
we define the following functionalities of the scheduler.
Scheduling
In the Scheduling phase, the
unique schedule to be used for all the dependence graphs is computed. The
goal of the scheduling is to find the optimal mappings of tasks onto processors,
such that the total computation time of the whole sweep can be
minimized.
For orthogonal grids, we have
KBA, Hybrid, and Volumetric methods. There are also options for the users
to define their own processor mappings. The theoretical analysis of these
algorithms can be found here.
For unstructured grids, we use the heuristics implemented in STAPL
Scheduler, namely wave front method, critical path method, heavy edge
merge, and dominant sequence clustering, to compute the best schedule for
the multiple dependence graphs.
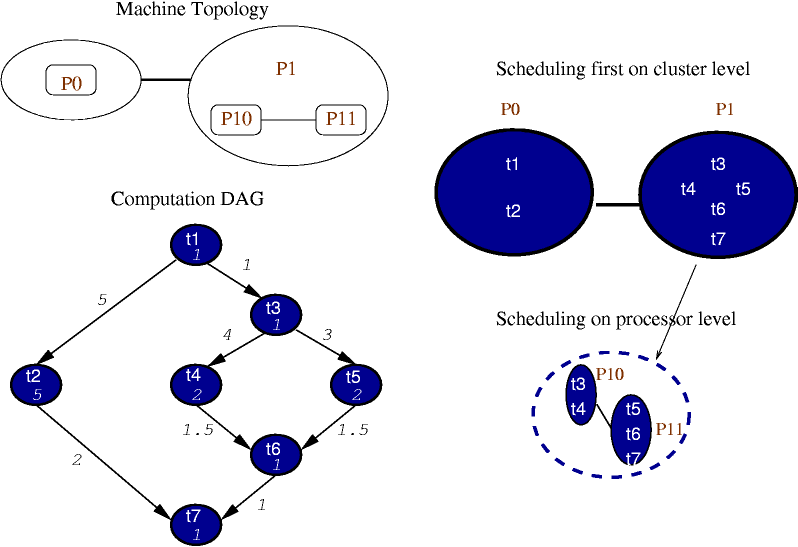
Due to the existence of various
machine topologies in supercomputing field, we adopt a hierarchical scheduling
policy, such that each processor partition can be scheduled iteratively
when necessary. In the following example, processor p1 can be viewed as
a virtual processor which represents two physical processors p10 and p11.
The hierarchical scheduling provides flexibility in mapping to different
machine topologies.
Cellset Aggregation
To further optimize the
computation, the scheduled computation graph is further clustered
into a graph on cellsets. Each node in the graph contains a set of cells,
which composes a computation block before each communication. The
purpose of aggregation is to properly overlap the computation and communication,
and balance the communication overhead with the cost of data transferring.
The optimal cellset size is machine dependent, and can be computed based
on machine parameters. There are theoretical analysis results for orthogonal
cases for the optimal cellset size (description here).
To get the optimal values for unstructured
grids, we can use simulation results.
Graph Transformation
Based on the sweep angles,
the aggregated cellset graph is transformed into different directed cellset
graph in this phase. The transformation is based on the angle between the
face normal of a pair of cellsets and the sweep angle. If the angle is
within 90 degree, there is a directed edge between the cellsets, otherwise,
there is no dependency between them.
Cell Ordering
Cell Ordering is to find
out the execution order of the cells in a cellset for different sweep angles.
The basic ordering uses a topological sort on the directed graph between cells.
Here is an implementation flow chart to show the major steps in the ASCI Scheduler implementation.
Load Balancing Techniques for Scalable Parallelization of Sampling-Based Motion Planning Algorithms, Adam Fidel, Sam Ade Jacobs, Shishir Sharma, Lawrence Rauchwerger, Nancy M. Amato, Technical Report, TR13-002 , Parasol Laboratory, Department of Computer Science, Texas A&M University, Mar 2013. Technical Report(pdf, abstract)
Task Scheduling and Parallel Mesh-Sweeps in Transport Computations, Nancy M. Amato, Ping An, Technical Report, TR00-009, Department of Computer Science and Engineering, Texas A&M University, Jan 2000. Technical Report(ps, pdf)