Related Publications
Parallel Hierarchical Composition Conflict-Based Search, Hannah Lee, James Motes, Marco Morales, Nancy M. Amato, IEEE/RSJ International Conference on Intelligent Robots and Systems, Vol: 6, Issue: 4, pp. 7001-7008, Prague, Czech Republic, Jul 2021. DOI: 10.1109/LRA.2021.3096476.
Keywords: Multi-Agent, Parallel Planning, Path Planning
Links : [Published]
BibTex
@article{lee2021parallel,
title={Parallel Hierarchical Composition Conflict-Based Search for Optimal Multi-Agent Pathfinding},
author={Lee, Hannah and Motes, James and Morales, Marco and Amato, Nancy M},
journal={IEEE Robotics and Automation Letters},
volume={6},
number={4},
pages={7001--7008},
year={2021},
publisher={IEEE}
}
Abstract
In this letter, we present the following optimal multi-agent pathfinding (MAPF) algorithms: Hierarchical Composition Conflict-Based Search, Parallel Hierarchical Composition Conflict-Based Search, and Dynamic Parallel Hierarchical Composition Conflict-Based Search. MAPF is the task of finding an optimal set of valid path plans for a set of agents such that no agents collide with present obstacles or each other. The presented algorithms are an extension of Conflict-Based Search (CBS), where the MAPF problem is solved by composing and merging smaller, more easily manageable subproblems. Using the information from these subproblems, the presented algorithms can more efficiently find an optimal solution. Our three presented algorithms demonstrate improved performance for optimally solving MAPF problems consisting of many agents in crowded areas while examining fewer states when compared with CBS and its variant Improved Conflict-Based Search.
Nested Parallelism with Algorithmic Skeletons, Alireza Majidi, Masters Thesis, Parasol Laboratory, Department of Computer Science, Texas A&M University, College Station, TX, USA, Jul 2020.
Keywords: Algorithmic Skeletons, Parallel Programming
Links : [Published]
BibTex
@mastersthesis{CitekeyMastersthesis,
author = "Alireza Majidi",
title = "Nested Parallelism with Algorithmic Skeletons",
school = "Texas A&M University",
year = 2020,
address = "College Station, TX, USA",
month = jul
}
Abstract
New trend in design of computer architectures, from memory hierarchy design to grouping computing units in different hierarchical levels in CPUs, pushes developers toward algorithms that can exploit these hierarchical designs. This trend makes support of nested-parallelism an important feature for parallel programming models. It enables implementation of parallel programs that can then be mapped onto the system hierarchy. However, supporting nested-parallelism is not a trivial task due to complexity in spawning nested sections, destructing them and more importantly communication between these nested parallel sections. Structured parallel programming models are proven to be a good choice since while they hide the parallel programming complexities from the programmers, they allow programmers to customize the algorithm execution without going through radical changes to the other parts of the program. In this thesis, nested algorithm composition in the STAPL Skeleton Library (SSL) is presented, which uses a nested dataflow model as its internal representation. We show how a high level program specification using SSL allows for asynchronous computation and improved locality. We study both the specification and performance of the STAPL implementation of Kripke, a mini-app developed by Lawrence Livermore National Laboratory. Kripke has multiple levels of parallelism and a number of data layouts, making it an excellent test bed to exercise the effectiveness of a nested parallel programming approach. Performance results are provided for six different nesting orders of the benchmark under different degrees of nested-parallelism, demonstrating the flexibility and performance of nested algorithmic skeleton composition in STAPL.
Provably Optimal Parallel Transport Sweeps on Semi-Structured Grids, Michael P. Adams, Marvin L. Adams, W. Daryl Hawkins, Timmie G. Smith, Lawrence Rauchwerger, Nancy M. Amato, Teresa S. Bailey, Robert D. Falgout, Adam Kunen, Peter Brown, Journal of Computational Physics, Vol: 407, Apr 2020. DOI: 10.1016/j.jcp.2020.109234
Keywords: Parallel Algorithms, Scientific Computing
Links : [Published]
BibTex
@article{DBLP:journals/jcphy/AdamsAHSRABFKB20,
author = {Michael P. Adams and
Marvin L. Adams and
W. Daryl Hawkins and
Timmie G. Smith and
Lawrence Rauchwerger and
Nancy M. Amato and
Teresa S. Bailey and
Robert D. Falgout and
Adam Kunen and
Peter Brown},
title = {Provably optimal parallel transport sweeps on semi-structured grids},
journal = {J. Comput. Phys.},
volume = {407},
pages = {109234},
year = {2020},
url = {https://doi.org/10.1016/j.jcp.2020.109234},
doi = {10.1016/j.jcp.2020.109234},
timestamp = {Fri, 27 Mar 2020 14:16:32 +0100},
biburl = {https://dblp.org/rec/journals/jcphy/AdamsAHSRABFKB20.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
Abstract
We have found provably optimal algorithms for full-domain discrete-ordinate transport sweeps on a class of grids in 2D and 3D Cartesian geometry that are regular at a coarse level but arbitrary within the coarse blocks. We describe these algorithms and show that they always execute the full eight-octant (or four-quadrant if 2D) sweep in the minimum possible number of stages for a given Px x Py x Pz partitioning. Computational results confirm that our optimal scheduling algorithms execute sweeps in the minimum possible stage count. Observed parallel efficiencies agree well with our performance model. Our PDT transport code has achieved approximately 68% parallel efficiency with > 1.5M parallel threads, relative to 8 threads, on a simple weak-scaling problem with only three energy groups, 10 direction per octant, and 4096 cells/core. We demonstrate similar efficiencies on a much more realistic set of nuclear-reactor test problems, with unstructured meshes that resolve fine geometric details. These results demonstrate that discrete-ordinates transport sweeps can be executed with high efficiency using more than 106 parallel processes.
Algorithm-Level Optimizations for Scalable Parallel Graph Processing, Harshvardhan, Doctoral dissertation, Parasol Laboratory, Department of Computer Science, Texas A&M University, College Station, TX, USA, May 2018.
Keywords: High-Performance Computing, Parallel Graph Algorithms, Parallel Libraries
Links : [Published]
BibTex
@phdthesis{CitekeyPhdthesis,
author = "Harshvardhan",
title = "Algorithm-Level Optimizations for Scalable Parallel Graph Processing",
school = "Texas A&M University",
address = "College Station, TX, USA",
year = 2018,
month = may
}
Abstract
Efficiently processing large graphs is challenging, since parallel graph algorithms suffer from poor scalability and performance due to many factors, including heavy communication and load-imbalance. Furthermore, it is difficult to express graph algorithms, as users need to understand and effectively utilize the underlying execution of the algorithm on the distributed system. The performance of graph algorithms depends not only on the characteristics of the system (such as latency, available RAM, etc.), but also on the characteristics of the input graph (small-world scalefree, mesh, long-diameter, etc.), and characteristics of the algorithm (sparse computation vs. dense communication). The best execution strategy, therefore, often heavily depends on the combination of input graph, system and algorithm. Fine-grained expression exposes maximum parallelism in the algorithm and allows the user to concentrate on a single vertex, making it easier to express parallel graph algorithms. However, this often loses information about the machine, making it difficult to extract performance and scalability from fine-grained algorithms. To address these issues, we present a model for expressing parallel graph algorithms using a fine-grained expression. Our model decouples the algorithm-writer from the underlying details of the system, graph, and execution and tuning of the algorithm. We also present various graph paradigms that optimize the execution of graph algorithms for various types of input graphs and systems. We show our model is general enough to allow graph algorithms to use the various graph paradigms for the best/fastest execution, and demonstrate good performance and scalability for various different graphs, algorithms, and systems to 100,000+ cores.
Bounded Asynchrony and Nested Parallelism for Scalable Graph Processing, Adam Fidel, Nancy M. Amato, Lawrence Rauchwerger, In Proc. Supercomputing (SC), Doctoral Showcase Poster, Denver, CO, Nov 2017.
Keywords: Approximate Algorithms, Parallel Graph Algorithms, STAPL
Links : [Published]
BibTex
N/A
Abstract
Processing large-scale graphs has become a critical component in a variety of fields, from scientific computing to social analytics. The irregular access pattern for graph workloads, coupled with complex graph structures and large data sizes makes efficiently executing parallel graph workloads challenging. In this dissertation, we develop two broad techniques for improving the performance of general parallel graph algorithms: bounded asynchrony and nested parallelism. Increasing asynchrony in a bounded manner allows one to avoid costly global synchronization at scale, while still avoiding the penalty of unbounded asynchrony including redundant work. Using this technique, we scale a BFS workload to 98,304 cores where traditional methods stop scaling. Additionally, asynchrony enables a new family of approximate algorithms for applications tolerant to fixed amounts of error. Representing graph algorithms in a nested parallel manner enables the full use of available parallelism inherent in graph algorithms, while efficiently managing communication through nested sections.
Fast Approximate Distance Queries in Unweighted Graphs using Bounded Asynchrony, Adam Fidel, Francisco Coral, Colton Riedel, Nancy M. Amato, Lawrence Rauchwerger, Workshop on Languages and Compilers for Parallel Computing (LCPC 2016). Lecture Notes in Computer Science, vol 10136. Springer, Cham., pp. 40-54, Rochester NY, USA, Jan 2017. DOI: 10.1007/978-3-319-52709-3_4
Keywords: Approximate Algorithms, Parallel Graph Algorithms, STAPL
Links : [Published]
BibTex
@inproceedings{
author="Adam Fidel and Francisco Coral Sabido and Colton Riedel and Nancy M. Amato and Lawrence Rauchwerger",
title="Fast Approximate Distance Queries in Unweighted Graphs using Bounded Asynchrony",
year=2017,
booktitle="Languages and Compilers for Parallel Computing (LCPC 2016)",
series="Lecture Notes in Computer Science",
volume="10136",
publisher="Springer, Cham",
note = "DOI: https://doi.org/10.1007/978-3-319-52709-3_4"
}
Abstract
We introduce a new parallel algorithm for approximate breadth-first ordering of an unweighted graph by using bounded asynchrony to parametrically control both the performance and error of the algorithm. This work is based on the k-level asynchronous (KLA) paradigm that trades expensive global synchronizations in the level-synchronous model for local synchronizations in the asynchronous model, which may result in redundant work. Instead of correcting errors introduced by asynchrony and redoing work as in KLA, in this work we control the amount of work that is redone and thus the amount of error allowed, leading to higher performance at the expense of a loss of precision. Results of an implementation of this algorithm are presented on up to 32,768 cores, showing 2.27x improvement over the exact KLA algorithm and 3.8x improvement over the level-synchronous version with minimal error on several graph inputs.
STAPL-RTS: A Runtime System for Massive Parallelism, Ioannis Papadopoulos, Doctoral dissertation, Parasol Laboratory, Department of Computer Science, Texas A&M University, College Station, TX, USA, May 2016.
Keywords: High-Performance Computing, Runtime Systems
Links : [Published]
BibTex
@phdthesis{CitekeyPhdthesis,
author = "Papadopoulos, Ioannis",
title = "STAPL-RTS: A Runtime System for Massive Parallelism",
school = "Texas A&M University",
address = "College Station, TX, USA",
year = 2016,
month = may
}
Abstract
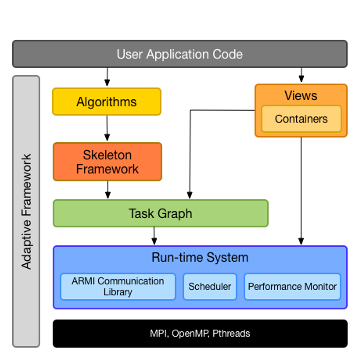
Modern High Performance Computing (HPC) systems are complex, with deep memory hierarchies and increasing use of computational heterogeneity via accelerators. When developing applications for these platforms, programmers are faced with two bad choices. On one hand, they can explicitly manage machine resources, writing programs using low level primitives from multiple APIs (e.g., MPI+OpenMP), creating efficient but rigid, difficult to extend, and non-portable implementations. Alternatively, users can adopt higher level programming environments, often at the cost of lost performance. Our approach is to maintain the high level nature of the application without sacrificing performance by relying on the transfer of high level, application semantic knowledge between layers of the software stack at an appropriate level of abstraction and performing optimizations on a per-layer basis. In this dissertation, we present the STAPL Runtime System (STAPL-RTS), a runtime system built for portable performance, suitable for massively parallel machines. While the STAPL-RTS abstracts and virtualizes the underlying platform for portability, it uses information from the upper layers to perform the appropriate low level optimizations that restore the performance characteristics. We outline the fundamental ideas behind the design of the STAPL-RTS, such as the always distributed communication model and its asynchronous operations. Through appropriate code examples and benchmarks, we prove that high level information allows applications written on top of the STAPL-RTS to attain the performance of optimized, but ad hoc solutions. Using the STAPL library, we demonstrate how this information guides important decisions in the STAPL-RTS, such as multi-protocol communication coordination and request aggregation using established C++ programming idioms. Recognizing that nested parallelism is of increasing interest for both expressivity and performance, we present a parallel model that combines asynchronous, one-sided operations with isolated nested parallel sections. Previous approaches to nested parallelism targeted either static applications through the use of blocking, isolated sections, or dynamic applications by using asynchronous mechanisms (i.e., recursive task spawning) which come at the expense of isolation. We combine the flexibility of dynamic task creation with the isolation guarantees of the static models by allowing the creation of asynchronous, one-sided nested parallel sections that work in tandem with the more traditional, synchronous, collective nested parallelism. This allows selective, run-time customizable use of parallelism in an application, based on the input and the algorithm.
Asynchronous Nested Parallelism for Dynamic Applications in Distributed Memory, Ioannis Papadopoulos, Nathan Thomas, Adam Fidel, Dielli Hoxha, Nancy M. Amato, Lawrence Rauchwerger, In Wkshp. on Lang. and Comp. for Par. Comp. (LCPC), pp. 106-121, Chapel Hill, NC, Feb 2016. DOI: 10.1007/978-3-319-29778-1_7
Keywords: Runtime Systems, STAPL
Links : [Published]
BibTex
@InProceedings{10.1007/978-3-319-29778-1_7,
author="Papadopoulos, Ioannis
and Thomas, Nathan
and Fidel, Adam
and Hoxha, Dielli
and Amato, Nancy M.
and Rauchwerger, Lawrence",
editor="Shen, Xipeng
and Mueller, Frank
and Tuck, James",
title="Asynchronous Nested Parallelism for Dynamic Applications in Distributed Memory",
booktitle="Languages and Compilers for Parallel Computing",
year="2016",
publisher="Springer International Publishing",
address="Cham",
pages="106--121",
abstract="Nested parallelism is of increasing interest for both expressivity and performance. Many problems are naturally expressed with this divide-and-conquer software design approach. In addition, programmers with target architecture knowledge employ nested parallelism for performance, imposing a hierarchy in the application to increase locality and resource utilization, often at the cost of implementation complexity.",
isbn="978-3-319-29778-1"
}
Abstract
Nested parallelism is of increasing interest for both expressivity and performance. Many problems are naturally expressed with this
divide-and-conquer software design approach. In addition, programmers with target architecture knowledge employ nested parallelism for
performance, imposing a hierarchy in the application to increase locality and resource utilization, often at the cost of implementation
complexity.
While dynamic applications are a natural fit for the approach, support for nested parallelism in distributed systems is generally limited
to well-structured applications engineered with distinct phases of intra-node computation and inter-node communication. This model makes
expressing irregular applications difficult and also hurts performance by introducing unnecessary latency and synchronizations. In this paper
we describe an approach to asynchronous nested parallelism which provides uniform treatment of nested computation across distributed memory. This
approach allows efficient execution while supporting dynamic applications which cannot be mapped onto the machine in the rigid manner of
regular applications. We use several graph algorithms as examples to demonstrate our libraryÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂs expressivity, flexibility, and performance.
An Algorithmic Approach to Communication Reduction in Parallel Graph Algorithms (Conference Best Paper Finalist), Harshvardhan, Adam Fidel, Nancy M. Amato, Lawrence Rauchwerger, In Proc. IEEE Int.Conf. on Parallel Architectures and Compilation Techniques (PACT), pp. 201-212, San Francisco, CA, Oct 2015. DOI: 10.1109/PACT.2015.34
Keywords: Parallel Graph Algorithms, STAPL
Links : [Published]
BibTex
@INPROCEEDINGS{7429306,
author={ {Harshvardhan} and A. {Fidel} and N. M. {Amato} and L. {Rauchwerger}},
booktitle={2015 International Conference on Parallel Architecture and Compilation (PACT)},
title={An Algorithmic Approach to Communication Reduction in Parallel Graph Algorithms},
year={2015},
volume={},
number={},
pages={201-212},}
Abstract
Graph algorithms on distributed-memory systems typically perform heavy communication, often limiting their scalability and performance. This work
presents an approach to transparently (without programmer intervention) allow fine-grained graph algorithms to utilize algorithmic communication
reduction optimizations. In many graph algorithms, the same information is communicated by a vertex to its neighbors, which we coin algorithmic
redundancy. Our approach exploits algorithmic redundancy to reduce communication between vertices located on different processing elements. We
employ algorithm-aware coarsening of messages sent during vertex visitation, reducing both the number of messages and the absolute amount
of communication in the system. To achieve this, the system structure is represented by a hierarchical graph, facilitating communication optimizations
that can take into consideration the machine's memory hierarchy. We also present an optimization for small-world scale-free graphs wherein hub
vertices (i.e., vertices of very large degree) are represented in a similar hierarchical manner, which is exploited to increase parallelism
and reduce communication. Finally, we present a framework that transparently allows fine-grained graph algorithms to utilize our hierarchical
approach without programmer intervention, while improving scalability and performance. Experimental results of our proposed approach on 131,000+
cores show improvements of up to a factor of 8 times over the non-hierarchical version for various graph mining and graph analytics algorithms.
Composing Algorithmic Skeletons to Express High-Performance Scientific Applications, Mani Zandifar, Mustafa Abdujabbar, Alireza Majidi, David Keyes, Nancy M. Amato, Lawrence Rauchwerger, In Proc. ACM Int. Conf. Supercomputing (ICS), pp. 415-424, Newport Beach, CA, USA. Conference Best Paper Award., Jun 2015. DOI: 10.1145/2751205.2751241
Keywords: Algorithmic Skeletons, Data Flow, STAPL
Links : [Published]
BibTex
@inproceedings{10.1145/2751205.2751241,
author = {Zandifar, Mani and Abdul Jabbar, Mustafa and Majidi, Alireza and Keyes, David and Amato, Nancy M. and Rauchwerger, Lawrence},
title = {Composing Algorithmic Skeletons to Express High-Performance Scientific Applications},
year = {2015},
isbn = {9781450335591},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/2751205.2751241},
doi = {10.1145/2751205.2751241},
abstract = {Algorithmic skeletons are high-level representations for parallel programs that hide the underlying parallelism details from program specification. These skeletons are defined in terms of higher-order functions that can be composed to build larger programs. Many skeleton frameworks support efficient implementations for stand-alone skeletons such as map, reduce, and zip for both shared-memory systems and small clusters. However, in these frameworks, expressing complex skeletons that are constructed through composition of fundamental skeletons either requires complete reimplementation or suffers from limited scalability due to required global synchronization. In the STAPL Skeleton Framework, we represent skeletons as parametric data flow graphs and describe composition of skeletons by point-to-point dependencies of their data flow graph representations. As a result, we eliminate the need for reimplementation and global synchronizations in composed skeletons. In this work, we describe the process of translating skeleton-based programs to data flow graphs and define rules for skeleton composition. To show the expressivity and ease of use of our framework, we show skeleton-based representations of the NAS EP, IS, and FT benchmarks. To show reusability and applicability of our framework on real-world applications we show an N-Body application using the FMM (Fast Multipole Method) hierarchical algorithm. Our results show that expressivity can be achieved without loss of performance even in complex real-world applications.},
booktitle = {Proceedings of the 29th ACM on International Conference on Supercomputing},
pages = {415–424},
numpages = {10},
keywords = {high-performance computing, data flow programming, distributed systems, algorithmic skeletons, patterns},
location = {Newport Beach, California, USA},
series = {ICS '15}
}
Abstract
Algorithmic skeletons are high-level representations for parallel programs that hide the underlying parallelism details from program specification. These skeletons are defined in terms of higher-order functions that can be composed to build larger programs. Many skeleton frameworks support efficient implementations for stand-alone skeletons such as map, reduce, and zip for both shared-memory systems and small clusters. However, in these frameworks, expressing complex skeletons that are constructed through composition of fundamental skeletons either requires complete reimplementation or suffers from limited scalability due to required global synchronization. In the STAPL Skeleton Framework, we represent skeletons as parametric data flow graphs and describe composition of skeletons by point-to-point dependencies of their data flow graph representations. As a result, we eliminate the need for reimplementation and global synchronizations in composed skeletons. In this work, we describe the process of translating skeleton-based programs to data flow graphs and define rules for skeleton composition. To show the expressivity and ease of use of our framework, we show skeleton-based representations of the NAS EP, IS, and FT benchmarks. To show reusability and applicability of our framework on real-world applications we show an N-Body application using the FMM (Fast Multipole Method) hierarchical algorithm. Our results show that expressivity can be achieved without loss of performance even in complex real-world applications.
STAPL-RTS: An Application Driven Runtime System, Ioannis Papadopoulos, Nathan Thomas, Adam Fidel, Nancy M. Amato, Lawrence Rauchwerger, In Proc. ACM Int. Conf. Supercomputing (ICS), pp. 425-434, Newport Beach, CA, USA, Jun 2015. DOI: 10.1145/2751205.2751233
Keywords: Communication Library, Runtime Systems, STAPL
Links : [Published]
BibTex
@inproceedings{10.1145/2751205.2751233,
author = {Papadopoulos, Ioannis and Thomas, Nathan and Fidel, Adam and Amato, Nancy M. and Rauchwerger, Lawrence},
title = {STAPL-RTS: An Application Driven Runtime System},
year = {2015},
isbn = {9781450335591},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/2751205.2751233},
doi = {10.1145/2751205.2751233},
abstract = {Modern HPC systems are growing in complexity, as they move towards deeper memory hierarchies and increasing use of computational heterogeneity via GPUs or other accelerators. When developing applications for these platforms, programmers are faced with two bad choices. On one hand, they can explicitly manage all machine resources, writing programs decorated with low level primitives from multiple APIs (e.g. Hybrid MPI / OpenMP applications). Though seemingly necessary for efficient execution, it is an inherently non-scalable way to write software. Without a separation of concerns, only small programs written by expert developers actually achieve this efficiency. Furthermore, the implementations are rigid, difficult to extend, and not portable. Alternatively, users can adopt higher level programming environments to abstract away these concerns. Extensibility and portability, however, often come at the cost of lost performance. The mapping of a user's application onto the system now occurs without the contextual information that was immediately available in the more coupled approach.In this paper, we describe a framework for the transfer of high level, application semantic knowledge into lower levels of the software stack at an appropriate level of abstraction. Using the STAPL library, we demonstrate how this information guides important decisions in the runtime system (STAPL-RTS), such as multi-protocol communication coordination and request aggregation. Through examples, we show how generic programming idioms already known to C++ programmers are used to annotate calls and increase performance.},
booktitle = {Proceedings of the 29th ACM on International Conference on Supercomputing},
pages = {425–434},
numpages = {10},
keywords = {data flow, shared memory, remote method invocation, distributed memory, parallel programming, runtime systems, application driven optimizations},
location = {Newport Beach, California, USA},
series = {ICS '15}
}
Abstract
Modern HPC systems are growing in complexity, as they move towards deeper memory hierarchies and increasing use of computational heterogeneity via GPUs or other accelerators. When developing applications for these platforms, programmers are faced with two bad choices. On one hand, they can explicitly manage all machine resources, writing programs decorated with low level primitives from multiple APIs (e.g. Hybrid MPI / OpenMP applications). Though seemingly necessary for efficient execution, it is an inherently non-scalable way to write software. Without a separation of concerns, only small programs written by expert developers actually achieve this efficiency. Furthermore, the implementations are rigid, difficult to extend, and not portable. Alternatively, users can adopt higher level programming environments to abstract away these concerns. Extensibility and portability, however, often come at the cost of lost performance. The mapping of a user's application onto the system now occurs without the contextual information that was immediately available in the more coupled approach.
In this paper, we describe a framework for the transfer of high level, application semantic knowledge into lower levels of the software stack at an appropriate level of abstraction. Using the STAPL library, we demonstrate how this information guides important decisions in the runtime system (STAPL-RTS), such as multi-protocol communication coordination and request aggregation. Through examples, we show how generic programming idioms already known to C++ programmers are used to annotate calls and increase performance.
A Hybrid Approach To Processing Big Data Graphs on Memory-Restricted Systems, Harshvardhan, Brandon West, Adam Fidel, Nancy M. Amato, Lawrence Rauchwerger, In Proc. Int. Par. and Dist. Proc. Symp. (IPDPS), pp. 799-808, Hyderabad, India, May 2015. DOI: 10.1109/IPDPS.2015.28
Keywords: Big Data, Parallel Graph Algorithms, STAPL
Links : [Published]
BibTex
@INPROCEEDINGS{7161566, author={ {Harshvardhan} and B. {West} and A. {Fidel} and N. M. {Amato} and L. {Rauchwerger}}, booktitle={2015 IEEE International Parallel and Distributed Processing Symposium}, title={A Hybrid Approach to Processing Big Data Graphs on Memory-Restricted Systems}, year={2015}, volume={}, number={}, pages={799-808},}
Abstract
With the advent of big-data, processing large graphs quickly has become increasingly important. Most existing approaches either utilize in-memory processing techniques that can only process graphs that fit completely in RAM, or disk-based techniques that sacrifice performance. In this work, we propose a novel RAM-Disk hybrid approach to graph processing that can scale well from a single shared-memory node to large distributed-memory systems. It works by partitioning the graph into sub graphs that fit in RAM and uses a paging-like technique to load sub graphs. We show that without modifying the algorithms, this approach can scale from small memory-constrained systems (such as tablets) to large-scale distributed machines with 16, 000+ cores.
A Hierarchical Approach to Reducing Communication in Parallel Graph Algorithms, Harshvardhan, Nancy M. Amato, Lawrence Rauchwerger, In Proc. ACM SIGPLAN Symp. Prin. Prac. Par. Prog. (PPOPP), pp. 285-286, San Francisco, CA, USA, Feb 2015. DOI: 10.1145/2688500.2700994
Keywords: Parallel Graph Algorithms, STAPL
Links : [Published]
BibTex
@inproceedings{10.1145/2688500.2700994,
author = {Harshvardhan and Amato, Nancy M. and Rauchwerger, Lawrence},
title = {A Hierarchical Approach to Reducing Communication in Parallel Graph Algorithms},
year = {2015},
isbn = {9781450332057},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/2688500.2700994},
doi = {10.1145/2688500.2700994},
abstract = { Large-scale graph computing has become critical due to the ever-increasing size of data. However, distributed graph computations are limited in their scalability and performance due to the heavy communication inherent in such computations. This is exacerbated in scale-free networks, such as social and web graphs, which contain hub vertices that have large degrees and therefore send a large number of messages over the network. Furthermore, many graph algorithms and computations send the same data to each of the neighbors of a vertex. Our proposed approach recognizes this, and reduces communication performed by the algorithm without change to user-code, through a hierarchical machine model imposed upon the input graph. The hierarchical model takes advantage of locale information of the neighboring vertices to reduce communication, both in message volume and total number of bytes sent. It is also able to better exploit the machine hierarchy to further reduce the communication costs, by aggregating traffic between different levels of the machine hierarchy. Results of an implementation in the STAPL GL shows improved scalability and performance over the traditional level-synchronous approach, with 2.5\texttimes{}-8\texttimes{} improvement for a variety of graph algorithms at 12,000+ cores. },
booktitle = {Proceedings of the 20th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming},
pages = {285–286},
numpages = {2},
keywords = {Distributed Computing, Graph Analytics, Parallel Graph Processing, Big Data},
location = {San Francisco, CA, USA},
series = {PPoPP 2015}
}
@article{10.1145/2858788.2700994,
author = {Harshvardhan and Amato, Nancy M. and Rauchwerger, Lawrence},
title = {A Hierarchical Approach to Reducing Communication in Parallel Graph Algorithms},
year = {2015},
issue_date = {August 2015},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {50},
number = {8},
issn = {0362-1340},
url = {https://doi.org/10.1145/2858788.2700994},
doi = {10.1145/2858788.2700994},
abstract = { Large-scale graph computing has become critical due to the ever-increasing size of data. However, distributed graph computations are limited in their scalability and performance due to the heavy communication inherent in such computations. This is exacerbated in scale-free networks, such as social and web graphs, which contain hub vertices that have large degrees and therefore send a large number of messages over the network. Furthermore, many graph algorithms and computations send the same data to each of the neighbors of a vertex. Our proposed approach recognizes this, and reduces communication performed by the algorithm without change to user-code, through a hierarchical machine model imposed upon the input graph. The hierarchical model takes advantage of locale information of the neighboring vertices to reduce communication, both in message volume and total number of bytes sent. It is also able to better exploit the machine hierarchy to further reduce the communication costs, by aggregating traffic between different levels of the machine hierarchy. Results of an implementation in the STAPL GL shows improved scalability and performance over the traditional level-synchronous approach, with 2.5\texttimes{}-8\texttimes{} improvement for a variety of graph algorithms at 12,000+ cores. },
journal = {SIGPLAN Not.},
month = jan,
pages = {285–286},
numpages = {2},
keywords = {Distributed Computing, Parallel Graph Processing, Big Data, Graph Analytics}
}
Abstract
Large-scale graph computing has become critical due to the ever-increasing size of data. However, distributed graph computations are limited in their scalability and performance due to the heavy communication inherent in such computations. This is exacerbated in scale-free networks, such as social and web graphs, which contain hub vertices that have large degrees and therefore send a large number of messages over the network. Furthermore, many graph algorithms and computations send the same data to each of the neighbors of a vertex. Our proposed approach recognizes this, and reduces communication performed by the algorithm without change to user-code, through a hierarchical machine model imposed upon the input graph. The hierarchical model takes advantage of locale information of the neighboring vertices to reduce communication, both in message volume and total number of bytes sent. It is also able to better exploit the machine hierarchy to further reduce the communication costs, by aggregating traffic between different levels of the machine hierarchy. Results of an implementation in the STAPL GL shows improved scalability and performance over the traditional level-synchronous approach, with 2.5ÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂ-8ÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂ improvement for a variety of graph algorithms at 12,000+ cores.
Efficient, Reachability-based, Parallel Algorithms for Finding Strongly Connected Components, Daniel Tomkins, Timmie Smith, Nancy M. Amato, Lawrence Rauchwerger, Technical Report, TR15-002, Parasol Laboratory, Department of Computer Science, Texas A&M University, College Station, TX 77843-3112, Jan 2015.
Keywords: Parallel Graph Algorithms, STAPL
Links : [Published]
BibTex
N/A
Abstract
Large, complex graphs are increasingly used to represent unstructured data in scientific applications. Applications such as discrete ordinates methods for radiation transport require these graphs to be directed with all cycles eliminated, where cycles are identified by finding the graph.s strongly connected components (SCCs). Deterministic parallel algorithms identify SCCs in polylogarithmic time, but the work of the algorithms on sparse graphs exceeds the linear sequential complexity bound. Randomized algorithms based on reachability ÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂ the ability to get from one vertex to another along a directed path ÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂ are generally favorable for sparse graphs, but either do not perform well on all graphs or introduce substantial overheads. This paper introduces two new algorithms, SCCMulti and SCCMulti-PriorityAware, which perform well on all graphs without significant overhead. We also provide a characterization that compares reachabilitybased SCC algorithms. Experimental results demonstrate scalability for both algorithms to 393,216 of cores on several types of graphs.
Faster Parallel Traversal of Scale Free Graphs at Extreme Scale with Vertex Delegates, Roger Pearce, Maya Gokhale, Nancy M. Amato, International Conference for High Performance Computing, Networking, Storage and Analysis (SC), pp. 549-559, New Orleans, Louisiana, USA, Nov 2014. DOI: 10.1109/SC.2014.50
Keywords: Parallel Graph Algorithms
Links : [Published]
BibTex
@inproceedings{DBLP:conf/sc/PearceGA14,
author = {Roger A. Pearce and
Maya B. Gokhale and
Nancy M. Amato},
editor = {Trish Damkroger and
Jack J. Dongarra},
title = {Faster Parallel Traversal of Scale Free Graphs at Extreme Scale with
Vertex Delegates},
booktitle = {International Conference for High Performance Computing, Networking,
Storage and Analysis, {SC} 2014, New Orleans, LA, USA, November 16-21,
2014},
pages = {549--559},
publisher = {{IEEE} Computer Society},
year = {2014},
url = {https://doi.org/10.1109/SC.2014.50},
doi = {10.1109/SC.2014.50},
timestamp = {Mon, 20 Apr 2020 17:14:43 +0200},
biburl = {https://dblp.org/rec/conf/sc/PearceGA14.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
Abstract
At extreme scale, irregularities in the structure of scale-free graphs such as social network graphs limit our ability to analyze these important and growing datasets. A key challenge is the presence of high-degree vertices (hubs), that leads to parallel workload and storage imbalances. The imbalances occur because existing partitioning techniques are not able to effectively partition high-degree vertices. We present techniques to distribute storage, computation, and communication of hubs for extreme scale graphs in distributed memory supercomputers. To balance the hub processing workload, we distribute hub data structures and related computation among a set of delegates. The delegates coordinate using highly optimized, yet portable, asynchronous broadcast and reduction operations. We demonstrate scalability of our new algorithmic technique using Breadth-First Search (BFS), Single Source Shortest Path (SSSP), K-Core Decomposition, and Page-Rank on synthetically generated scale-free graphs. Our results show excellent scalability on large scale-free graphs up to 131K cores of the IBM BG/P, and outperform the best known Graph500 performance on BG/P Intrepid by 15%.
Validation of Full-Domain Massively Parallel Transport Sweep Algorithms, eresa S. Bailey, W. Daryl Hawkins, Marvin L. Adams, Peter N. Brown, Adam J. Kunen, Michael P. Adams, Timmie Smith, Nancy M. Amato, and Lawrence Rauchwerger, Transactions of the American Nuclear Society, Vol: 111, Issue: 1, pp. 699-702, Anaheim, CA, USA, Nov 2014.
Keywords: Parallel Algorithms, Scientific Computing, STAPL
Links : [Published]
BibTex
@article{bailey--tans-2014
, author = "Teresa S. Bailey and W. Daryl Hawkins and Marvin L. Adams and Peter N. Brown and Adam J. Kunen and Michael P. Adams and Timmie Smith and Nancy M. Amato and Lawrence Rauchwerger"
, title = "Validation of Full-Domain Massively Parallel Transport Sweep Algorithms"
, journal = "Trans. American Nuclear Society"
, volume = "111"
, month = "November"
, year = "2014"
, pages = "699-702"
, note = "2014 ANS Annual Winter Meeting; Nov 9-13, 2014, Anaheim, CA, USA"
}
Abstract
The scalability of sweep algorithms has been a somewhat disputed topic recently. Some papers have predicted that these algorithms will scale if applied appropriately, while others have claimed that sweep algorithms have limited scalability. We compare the parallel performance models for sweep algorithms to actual computational performance using two distinctly different discrete ordinates transport codes. We have run both codes beyond 1Million MPI ranks on Lawrence Livermore National LaboratoryâÂÂs (LLNL) BGQ machines (SEQUOIA and VULCAN).
The STAPL Skeleton Framework, Mani Zandifar, Nathan Thomas, Nancy M. Amato, Lawrence Rauchwerger, In Wkshp. on Lang. and Comp. for Par. Comp. (LCPC), pp. 176-190, Hillsboro, OR, USA, Sep 2014. DOI: 10.1007/978-3-319-17473-0_12
Keywords: Data Flow, Parallel Libraries, STAPL
Links : [Published]
BibTex
@InProceedings{10.1007/978-3-319-17473-0_12,
author="Zandifar, Mani
and Thomas, Nathan
and Amato, Nancy M.
and Rauchwerger, Lawrence",
editor="Brodman, James
and Tu, Peng",
title="The stapl Skeleton Framework",
booktitle="Languages and Compilers for Parallel Computing",
year="2015",
publisher="Springer International Publishing",
address="Cham",
pages="176--190",
abstract="This paper describes the stapl Skeleton Framework, a high-level skeletal approach for parallel programming. This framework abstracts the underlying details of data distribution and parallelism from programmers and enables them to express parallel programs as a composition of existing elementary skeletons such as map, map-reduce, scan, zip, butterfly, allreduce, alltoall and user-defined custom skeletons.",
isbn="978-3-319-17473-0"
}
Abstract
This paper describes the stapl Skeleton Framework, a high-level skeletal approach for parallel programming. This framework abstracts the underlying details of data distribution and parallelism from programmers and enables them to express parallel programs as a composition of existing elementary skeletons such as map, map-reduce, scan, zip, butterfly, allreduce, alltoall and user-defined custom skeletons.
Skeletons in this framework are defined as parametric data flow graphs, and their compositions are defined in terms of data flow graph compositions. Defining the composition in this manner allows dependencies between skeletons to be defined in terms of point-to-point dependencies, avoiding unnecessary global synchronizations. To show the ease of composability and expressivity, we implemented the NAS Integer Sort (IS) and Embarrassingly Parallel (EP) benchmarks using skeletons and demonstrate comparable performance to the hand-optimized reference implementations. To demonstrate scalable performance, we show a transformation which enables applications written in terms of skeletons to run on more than 100,000 cores.
KLA: A New Algorithmic Paradigm for Parallel Graph Computations (Conference Best Paper), Harshvardhan, Adam Fidel, Nancy M. Amato, Lawrence Rauchwerger, In Proc. IEEE Int.Conf. on Parallel Architectures and Compilation Techniques (PACT), pp. 27-38, Edmonton, AB, Canada, Aug 2014. DOI: 10.1145/2628071.2628091
Keywords: Parallel Algorithms, Parallel Graph Algorithms, STAPL
Links : [Published]
BibTex
@inproceedings{10.1145/2628071.2628091,
author = {Harshvardhan and Fidel, Adam and Amato, Nancy M. and Rauchwerger, Lawrence},
title = {KLA: A New Algorithmic Paradigm for Parallel Graph Computations},
year = {2014},
isbn = {9781450328098},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/2628071.2628091},
doi = {10.1145/2628071.2628091},
abstract = {This paper proposes a new algorithmic paradigm - k-level asynchronous (KLA) - that bridges level-synchronous and asynchronous paradigms for processing graphs. The KLA paradigm enables the level of asynchrony in parallel graph algorithms to be parametrically varied from none (level-synchronous) to full (asynchronous). The motivation is to improve execution times through an appropriate trade-off between the use of fewer, but more expensive global synchronizations, as in level-synchronous algorithms, and more, but less expensive local synchronizations (and perhaps also redundant work), as in asynchronous algorithms. We show how common patterns in graph algorithms can be expressed in the KLA pardigm and provide techniques for determining k, the number of asynchronous steps allowed between global synchronizations. Results of an implementation of KLA in the STAPL Graph Library show excellent scalability on up to 96K cores and improvements of 10x or more over level-synchronous and asynchronous versions for graph algorithms such as breadth-first search, PageRank, k-core decomposition and others on certain classes of real-world graphs.},
booktitle = {Proceedings of the 23rd International Conference on Parallel Architectures and Compilation},
pages = {27–38},
numpages = {12},
keywords = {parallel algorithms, big data, distributed computing, graph analytics, asynchronous graph algorithms},
location = {Edmonton, AB, Canada},
series = {PACT '14}
}
Abstract
This paper proposes a new algorithmic paradigm - k-level asynchronous (KLA) - that bridges level-synchronous and asynchronous paradigms for processing graphs. The KLA paradigm enables the level of asynchrony in parallel graph algorithms to be parametrically varied from none (level-synchronous) to full (asynchronous). The motivation is to improve execution times through an appropriate trade-off between the use of fewer, but more expensive global synchronizations, as in level-synchronous algorithms, and more, but less expensive local synchronizations (and perhaps also redundant work), as in asynchronous algorithms. We show how common patterns in graph algorithms can be expressed in the KLA pardigm and provide techniques for determining k, the number of asynchronous steps allowed between global synchronizations. Results of an implementation of KLA in the STAPL Graph Library show excellent scalability on up to 96K cores and improvements of 10ÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂ or more over level-synchronous and asynchronous versions for graph algorithms such as breadth-first search, PageRank, k-core decomposition and others on certain classes of real-world graphs.
From Petascale to the Pocket: Adaptively Scaling Parallel Programs for Mobile SoCs, Adam Fidel, Nancy M. Amato, Lawrence Rauchwerger, In Proc. IEEE Int.Conf. on Parallel Architectures and Compilation Techniques (PACT), SRC Poster, pp. 511-512, Edmonton, AB, Canada, Aug 2014. DOI: 10.1145/2628071.2671426
Keywords: Parallel Programming, STAPL
Links : [Published]
BibTex
@inproceedings{10.1145/2628071.2671426,
author = {Fidel, Adam and Amato, Nancy M. and Rauchwerger, Lawrence},
title = {From Petascale to the Pocket: Adaptively Scaling Parallel Programs for Mobile SoCs},
year = {2014},
isbn = {9781450328098},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/2628071.2671426},
doi = {10.1145/2628071.2671426},
booktitle = {Proceedings of the 23rd International Conference on Parallel Architectures and Compilation},
pages = {511–512},
numpages = {2},
keywords = {energy-efficient computing, parallel libraries, shared memory optimization},
location = {Edmonton, AB, Canada},
series = {PACT '14}
}
Abstract
With resource-constrained mobile and embedded devices being outfitted with multicore processors, there exists a need to allow existing parallel programs to be scaled down to efficiently utilize these devices. We study the marriage of programming models originally designed for distributed-memory supercomputers with smaller scale parallel architectures that are shared-memory and generally resource-constrained.
Processing Big Data Graphs on Memory-Restricted Systems, Harshvardhan, Nancy M. Amato, Lawrence Rauchwerger, In Proc. IEEE Int.Conf. on Parallel Architectures and Compilation Techniques (PACT), pp. 517-518, Edmonton, AB, Canada, Aug 2014. DOI: 10.1145/2628071.2671429
Keywords: Big Data, Out-Of-Core Graph Algorithms, Parallel Graph Algorithms
Links : [Published]
BibTex
@inproceedings{10.1145/2628071.2671429,
author = {Harshvardhan and Amato, Nancy M. and Rauchweger, Lawrence},
title = {Processing Big Data Graphs on Memory-Restricted Systems},
year = {2014},
isbn = {9781450328098},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/2628071.2671429},
doi = {10.1145/2628071.2671429},
abstract = {With the advent of big-data, processing large graphs quickly has become increasingly important. Most existing approaches either utilize in-memory processing techniques, which can only process graphs that fit completely in RAM, or disk-based techniques that sacrifice performance.In this work, we propose a novel RAM-Disk hybrid approach to graph processing that can scale well from a single shared-memory node to large distributed-memory systems. It works by partitioning the graph into subgraphs that fit in RAM and uses a paging-like technique to load subgraphs. We show that without modifying the algorithms, this approach can scale from small memory-constrained systems (such as tablets) to large-scale distributed machines with 16,000+ cores.},
booktitle = {Proceedings of the 23rd International Conference on Parallel Architectures and Compilation},
pages = {517–518},
numpages = {2},
keywords = {out-of-core graph algorithms, distributed computing, graph analytics, big data, parallel graph processing},
location = {Edmonton, AB, Canada},
series = {PACT '14}
}
Abstract
With the advent of big-data, processing large graphs quickly has become increasingly important. Most existing approaches either utilize in-memory processing techniques, which can only process graphs that fit completely in RAM, or disk-based techniques that sacrifice performance. Contribution. In this work, we propose a novel RAM-Disk hybrid approach to graph processing that can scale well from a single shared-memory node to large distributed-memory systems. It works by partitioning the graph into subgraphs that fit in RAM and uses a paging-like technique to load subgraphs. We show that without modifying the algorithms, this approach can scale from small memory-constrained systems (such as tablets) to large-scale distributed machines with 16, 000+ cores.
Using Load Balancing to Scalably Parallelize Sampling-Based Motion Planning Algorithms, Adam Fidel, Sam Ade Jacobs, Shishir Sharma, Nancy M. Amato, Lawrence Rauchwerger, 2014 IEEE 28th International Parallel and Distributed Processing Symposium, pp. 573-582, Phoenix, AZ, USA, May 2014. DOI: 10.1109/IPDPS.2014.66
Keywords: Parallel Algorithms, Parallel Planning, Sampling-Based Motion Planning
Links : [Published]
BibTex
@INPROCEEDINGS{6877290, author={A. {Fidel} and S. A. {Jacobs} and S. {Sharma} and N. M. {Amato} and L. {Rauchwerger}}, booktitle={2014 IEEE 28th International Parallel and Distributed Processing Symposium}, title={Using Load Balancing to Scalably Parallelize Sampling-Based Motion Planning Algorithms}, year={2014}, volume={}, number={}, pages={573-582}, doi={10.1109/IPDPS.2014.66}}
Abstract
Motion planning, which is the problem of computing feasible paths in an environment for a movable object, has applications in many domains ranging from robotics, to intelligent CAD, to protein folding. The best methods for solving this PSPACE-hard problem are so-called sampling-based planners. Recent work introduced uniform spatial subdivision techniques for parallelizing sampling-based motion planning algorithms that scaled well. However, such methods are prone to load imbalance, as planning time depends on region characteristics and, for most problems, the heterogeneity of the sub problems increases as the number of processors increases. In this work, we introduce two techniques to address load imbalance in the parallelization of sampling-based motion planning algorithms: an adaptive work stealing approach and bulk-synchronous redistribution. We show that applying these techniques to representatives of the two major classes of parallel sampling-based motion planning algorithms, probabilistic roadmaps and rapidly-exploring random trees, results in a more scalable and load-balanced computation on more than 3,000 cores.
A Scalable Framework for Parallelizing Sampling-Based Motion Planning Algorithms, Samson Ade Jacobs, Doctoral Dissertation, Texas A&M University, College Station, Texas, USA, May 2014.
Keywords: Parallel Algorithms, Parallel Planning, Sampling-Based Motion Planning
Links : [Published]
BibTex
@phdthesis{jacobs2014scalable,
title={A Scalable Framework for Parallelizing Sampling-Based Motion Planning Algorithms},
author={Jacobs, Samson Ade},
year={2014}
}
Abstract
Motion planning is defined as the problem of finding a valid path taking a robot (or any movable object) from a given start configuration to a goal configuration in an environment. While motion planning has its roots in robotics, it now finds application in many other areas of scientific computing such as protein folding, drug design, virtual prototyping, computer-aided design (CAD), and computer animation. These new areas test the limits of the best sequential planners available, motivating the need for methods that can exploit parallel processing. This dissertation focuses on the design and implementation of a generic and scalable framework for parallelizing motion planning algorithms. In particular, we focus on sampling-based motion planning algorithms which are considered to be the state-of-the-art. Our work covers the two broad classes of sampling-based motion planning algorithms--the graph-based and the tree-based methods. Central to our approach is the subdivision of the planning space into regions. These regions represent sub- problems that can be processed in parallel. Solutions to the sub-problems are later combined to form a solution to the entire problem. By subdividing the planning space and restricting the locality of connection attempts to adjacent regions, we reduce the work and inter-processor communication associated with nearest neighbor calculation, a critical bottleneck for scalability in existing parallel motion planning methods. We also describe how load balancing strategies can be applied in complex environments. We present experimental results that scale to thousands of processors on different massively parallel machines for a range of motion planning problems.
Adaptive Neighbor Connection for PRMs: A Natural Fit for Heterogeneous Environments and Parallelism, Chinwe Ekenna, Sam Ade Jacobs, Shawna Thomas, Nancy M. Amato, In. Proc. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, Nov 2013. DOI: 10.1109/IROS.2013.6696510
Keywords: Parallel Algorithms, Parallel Planning, Sampling-Based Motion Planning
Links : [Published]
BibTex
@INPROCEEDINGS{6696510, author={C. {Ekenna} and S. A. {Jacobs} and S. {Thomas} and N. M. {Amato}}, booktitle={2013 IEEE/RSJ International Conference on Intelligent Robots and Systems}, title={Adaptive neighbor connection for PRMs: A natural fit for heterogeneous environments and parallelism}, year={2013}, volume={}, number={}, pages={1249-1256}, doi={10.1109/IROS.2013.6696510}}
Abstract
Probabilistic Roadmap Methods (PRMs) are widely used motion planning methods that sample robot configurations (nodes) and connect them to form a graph (roadmap) containing feasible trajectories. Many PRM variants propose different strategies for each of the steps and choosing among them is problem dependent. Planning in heterogeneous environments and/or on parallel machines necessitates dividing the problem into regions where these choices have to be made for each one. Hand-selecting the best method for each region becomes infeasible. In particular, there are many ways to select connection candidates, and choosing the appropriate strategy is input dependent. In this paper, we present a general connection framework that adaptively selects a neighbor finding strategy from a candidate set of options. Our framework learns which strategy to use by examining their success rates and costs. It frees the user of the burden of selecting the best strategy and allows the selection to change over time. We perform experiments on rigid bodies of varying geometry and articulated linkages up to 37 degrees of freedom. Our results show that strategy performance is indeed problem/region dependent, and our adaptive method harnesses their strengths. Over all problems studied, our method differs the least from manual selection of the best method, and if one were to manually select a single method across all problems, the performance can be quite poor. Our method is able to adapt to changing sampling density and learns different strategies for each region when the problem is partitioned for parallelism.
Blind RRT: A Probabilistically Complete Distributed RRT, Cesar Rodriguez, Jory Denny, Sam Ade Jacobs, Shawna Thomas, Nancy M. Amato, In. Proc. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, Nov 2013. DOI: 10.1109/IROS.2013.6696587
Keywords: Parallel Planning, Rapidly-exploring Random Tree (RRT), Sampling-Based Motion Planning
Links : [Published]
BibTex
@INPROCEEDINGS{6696587, author={C. {Rodriguez} and J. {Denny} and S. A. {Jacobs} and S. {Thomas} and N. M. {Amato}}, booktitle={2013 IEEE/RSJ International Conference on Intelligent Robots and Systems}, title={Blind RRT: A probabilistically complete distributed RRT}, year={2013}, volume={}, number={}, pages={1758-1765}, doi={10.1109/IROS.2013.6696587}}
Abstract
Rapidly-Exploring Random Trees (RRTs) have been successful at finding feasible solutions for many types of problems. With motion planning becoming more computationally demanding, we turn to parallel motion planning for efficient solutions. Existing work on distributed RRTs has been limited by the overhead that global communication requires. A recent approach, Radial RRT, demonstrated a scalable algorithm that subdivides the space into regions to increase the computation locality. However, if an obstacle completely blocks RRT growth in a region, the planning space is not covered and is thus not probabilistically complete. We present a new algorithm, Blind RRT, which ignores obstacles during initial growth to efficiently explore the entire space. Because obstacles are ignored, free components of the tree become disconnected and fragmented. Blind RRT merges parts of the tree that have become disconnected from the root. We show how this algorithm can be applied to the Radial RRT framework allowing both scalability and effectiveness in motion planning. This method is a probabilistically complete approach to parallel RRTs. We show that our method not only scales but also overcomes the motion planning limitations that Radial RRT has in a series of difficult motion planning tasks.
A scalable distributed RRT for motion planning, Sam Ade Jacobs, Nicholas Stradford, Cesar Rodriguez, Shawna Thomas, Nancy M. Amato, 2013 IEEE International Conference on Robotics and Automation, pp. 5088-5095, Karlsruhe, Germany, May 2013. DOI: 10.1109/ICRA.2013.6631304
Keywords: Parallel Planning, Rapidly-exploring Random Tree (RRT), Sampling-Based Motion Planning
Links : [Published]
BibTex
@INPROCEEDINGS{6631304,
author={S. A. {Jacobs} and N. {Stradford} and C. {Rodriguez} and S. {Thomas} and N. M. {Amato}},
booktitle={2013 IEEE International Conference on Robotics and Automation},
title={A scalable distributed RRT for motion planning},
year={2013},
volume={},
number={},
pages={5088-5095},
doi={10.1109/ICRA.2013.6631304}}
Abstract
Rapidly-exploring Random Tree (RRT), like other sampling-based motion planning methods, has been very successful in solving motion planning problems. Even so, sampling-based planners cannot solve all problems of interest efficiently, so attention is increasingly turning to parallelizing them. However, one challenge in parallelizing RRT is the global computation and communication overhead of nearest neighbor search, a key operation in RRTs. This is a critical issue as it limits the scalability of previous algorithms. We present two parallel algorithms to address this problem. The first algorithm extends existing work by introducing a parameter that adjusts how much local computation is done before a global update. The second algorithm radially subdivides the configuration space into regions, constructs a portion of the tree in each region in parallel, and connects the subtrees,i removing cycles if they exist. By subdividing the space, we increase computation locality enabling a scalable result. We show that our approaches are scalable. We present results demonstrating almost linear scaling to hundreds of processors on a Linux cluster and a Cray XE6 machine.
Load Balancing Techniques for Scalable Parallelization of Sampling-Based Motion Planning Algorithms, Adam Fidel, Sam Ade Jacobs, Shishir Sharma, Lawrence Rauchwerger, Nancy M. Amato, Technical Report, TR13-002 , Parasol Laboratory, Department of Computer Science, Texas A&M University, College Station, TX, USA, Mar 2013.
Keywords: Parallel Planning, Sampling-Based Motion Planning, STAPL
Links : [Manuscript]
BibTex
@techreport{afidel-tr13-002-2013,
title = "Load Balancing Techniques for Scalable Parallelization of Sampling-Based Motion Planning Algorithms",
author = "Fidel, Adam and Jacobs, Sam Ade and Sharma, Shishir and Rauchwerger, Lawrence and Amato, Nancy M. ",
institution = "Texas A&M University",
address = "College Station, TX, USA",
number = "TR13-002",
year = 2013,
month = mar
}
Abstract
Motion planning, which is the problem of computing feasible paths through an environment for a movable object, has applications in many domains ranging from robotics, to intelligent CAD, to protein folding. The best methods for solving this PSPACE-hard problem are so-called sampling-based planners. Recent work introduced uniform spatial subdivision techniques for parallelizing sampling-based motion planning algorithms that scaled well. However, such methods are prone to load imbalance, particularly as the number of processors is increased, because planning time depends on region characteristics and, for most problems, the heterogeneity of the set of regions increases as the region size decreases. In this work, we introduce two techniques to address the problems of load imbalance in the parallelization of sampling-based motion planning algorithms: bulk-synchronous redistribution and an adaptive workstealing approach. We show that applying these techniques to representatives of the two major classes of parallel sampling-based motion planning algorithms, probabilistic roadmaps and rapidly-exploring
random trees, results in a more scalable and load-balanced computation on 3,000+ cores.
Efficient Massively Parallel Transport Sweeps, W. Daryl Hawkins, Timmie Smith, Michael P. Adams, Lawrence Rauchwerger, Nancy Amato, Marvin L. Adams, Transactions of the American Nuclear Society, Vol: 107, Issue: 1, pp. 477-481, San Diego, CA, USA, Nov 2012.
Keywords: Parallel Algorithms, Scientific Computing, STAPL
Links : [Published]
BibTex
@article{hawkins-tans-2012
, author = "W. Daryl Hawkins and Timmie Smith and Michael P. Adams and Lawrence Rauchwerger and Nancy Amato and Marvin L. Adams"
, title = "Efficient Massively Parallel Transport Sweeps"
, journal = "Trans. American Nuclear Society"
, volume = "107"
, number = "1"
, month = "November"
, year = "2012"
, pages = "477-481"
, issn = "0003-018X"
, note = "2012 ANS Annual Winter Meeting ; Conference date: 11-11-2012 Through 15-11-2012",
}
Abstract
The full-domain âÃÂÃÂsweep,âÃÂàin which all angular fluxes in a problem are calculated given previous-iterate values only for the volumetric source, forms the foundation for many iterative methods that have desirable properties. One important property is that iteration counts do not grow with mesh refinement. The sweep solution on parallel machines is complicated by the dependency of a given cell on its upstream neighbors. A sweep algorithm is defined by its partitioning (dividing the domain among processors), aggregation (grouping cells, directions, and energy groups into âÃÂÃÂtasksâÃÂÃÂ), and scheduling (choosing which task to execute if more than one is available). The work presented here follows that of Bailey and Falgout, who theoretically and computationally evaluated the performance of three sweep algorithms. Their âÃÂÃÂdata-drivenâÃÂàschedule appeared to be optimalâÃÂÃÂexecuting the sweep in the minimum possible number of stagesâÃÂÃÂfor tested partitionings and aggregations, but they were unable to prove this mathematically and they did not attempt to optimize across possible partitionings and aggregations. Here we consider 3D Cartesian grids of Nx ÃÂàNy ÃÂàNz spatial cells and simple Px ÃÂàPy ÃÂàPz partitioning, and we permit general aggregation of cells, directions, and energy groups. We have found a provably optimal
family of scheduling algorithms and we present results from one of these. We exploit our guaranteed minimum stage count to further optimize sweep-execution time by choosing the best possible partitioning and aggregation parameters. Our results show excellent scaling out to 32,768 cores, significantly better than results previously reported for sweeps and in line with the optimistic projections.
The STAPL Parallel Graph Library, Harshvardhan, Adam Fidel, Nancy M. Amato, Lawrence Rauchwerger, Languages and Compilers for Parallel Computing (LCPC), pp. 46-60, Tokyo, Japan, Sep 2012. DOI: 10.1007/978-3-642-37658-0_4
Keywords: Parallel Graph Algorithms, STAPL
Links : [Published]
BibTex
@InProceedings{10.1007/978-3-642-37658-0_4,
author=\"Harshvardhan
and Fidel, Adam
and Amato, Nancy M.
and Rauchwerger, Lawrence\",
editor=\"Kasahara, Hironori
and Kimura, Keiji\",
title=\"The STAPL Parallel Graph Library\",
booktitle=\"Languages and Compilers for Parallel Computing\",
year=\"2013\",
publisher=\"Springer Berlin Heidelberg\",
address=\"Berlin, Heidelberg\",
pages=\"46--60\",
abstract=\"This paper describes the stapl Parallel Graph Library, a high-level framework that abstracts the user from data-distribution and parallelism details and allows them to concentrate on parallel graph algorithm development. It includes a customizable distributed graph container and a collection of commonly used parallel graph algorithms. The library introduces pGraphpViews that separate algorithm design from the container implementation. It supports three graph processing algorithmic paradigms, level-synchronous, asynchronous and coarse-grained, and provides common graph algorithms based on them. Experimental results demonstrate improved scalability in performance and data size over existing graph libraries on more than 16,000 cores and on internet-scale graphs containing over 16 billion vertices and 250 billion edges.\",
isbn=\"978-3-642-37658-0\"
}
Abstract
This paper describes the stapl Parallel Graph Library, a high-level framework that abstracts the user from data-distribution and parallelism details and allows them to concentrate on parallel graph algorithm development. It includes a customizable distributed graph container and a collection of commonly used parallel graph algorithms. The library introduces pGraph pViews that separate algorithm design from the container implementation. It supports three graph processing algorithmic paradigms, level-synchronous, asynchronous and coarse-grained, and provides common graph algorithms based on them. Experimental results demonstrate improved scalability in performance and data size over existing graph libraries on more than 16,000 cores and on internet-scale graphs containing over 16 billion vertices and 250 billion edges.
A Scalable Method for Parallelizing Sampling-Based Motion Planning Algorithms, Sam Ade Jacobs, Kasra Manavi, Juan Burgos, Jory Denny, Shawna Thomas, Nancy M. Amato, 2012 IEEE International Conference on Robotics and Automation, pp. 2529-2536, Saint Paul, MN, USA, May 2012. DOI: 10.1109/ICRA.2012.6225334
Keywords: Parallel Algorithms, Parallel Planning, Sampling-Based Motion Planning
Links : [Published]
BibTex
@INPROCEEDINGS{6225334,
author={S. A. {Jacobs} and K. {Manavi} and J. {Burgos} and J. {Denny} and S. {Thomas} and N. M. {Amato}},
booktitle={2012 IEEE International Conference on Robotics and Automation},
title={A scalable method for parallelizing sampling-based motion planning algorithms},
year={2012},
volume={},
number={},
pages={2529-2536},
doi={10.1109/ICRA.2012.6225334}}
Abstract
This paper describes a scalable method for parallelizing sampling-based motion planning algorithms. It subdivides configuration space (C-space) into (possibly overlapping) regions and independently, in parallel, uses standard (sequential) sampling-based planners to construct roadmaps in each region. Next, in parallel, regional roadmaps in adjacent regions are connected to form a global roadmap. By subdividing the space and restricting the locality of connection attempts, we reduce the work and inter-processor communication associated with nearest neighbor calculation, a critical bottleneck for scalability in existing parallel motion planning methods. We show that our method is general enough to handle a variety of planning schemes, including the widely used Probabilistic Roadmap (PRM) and Rapidly-exploring Random Trees (RRT) algorithms. We compare our approach to two other existing parallel algorithms and demonstrate that our approach achieves better and more scalable performance. Our approach achieves almost linear scalability on a 2400 core LINUX cluster and on a 153,216 core Cray XE6 petascale machine.
The STAPL Parallel Container Framework, Ilie Gabriel Tanase, Doctoral dissertation, Parasol Laboratory, Department of Computer Science, Texas A&M University, College Station, TX, USA, Feb 2012.
Keywords: Parallel Containers, Parallel Libraries
Links : [Published]
BibTex
@phdthesis{CitekeyPhdthesis,
author = "Tanase, Ilie Gabriel",
title = "The STAPL Parallel Container Framework",
school = "Texas A&M University",
address = "College Station, TX, USA",
year = 2012,
month = feb
}
Abstract
The Standard Template Adaptive Parallel Library (STAPL) is a parallel programming infrastructure that extends C with support for parallelism. STAPL provides a run-time system, a collection of distributed data structures (pContainers) and parallel algorithms (pAlgorithms), and a generic methodology for extending them to provide customized functionality. Parallel containers are data structures addressing issues related to data partitioning, distribution, communication, synchronization, load balancing, and thread safety. This dissertation presents the STAPL Parallel Container Framework (PCF), which is designed to facilitate the development of generic parallel containers. We introduce a set of concepts and a methodology for assembling a pContainer from existing sequential or parallel containers without requiring the programmer to deal with concurrency or data distribution issues. The STAPL PCF provides a large number of basic data parallel structures (e.g., pArray, pList, pVector, pMatrix, pGraph, pMap, pSet). The STAPL PCF is distinguished from existing work by offering a class hierarchy and a composition mechanism which allows users to extend and customize the current container base for improved application expressivity and performance. We evaluate the performance of the STAPL pContainers on various parallel machines including a massively parallel CRAY XT4 system and an IBM P5-575 cluster. We show that the pContainer methods, generic pAlgorithms, and different applications, all provide good scalability on more than 10^4 processors.
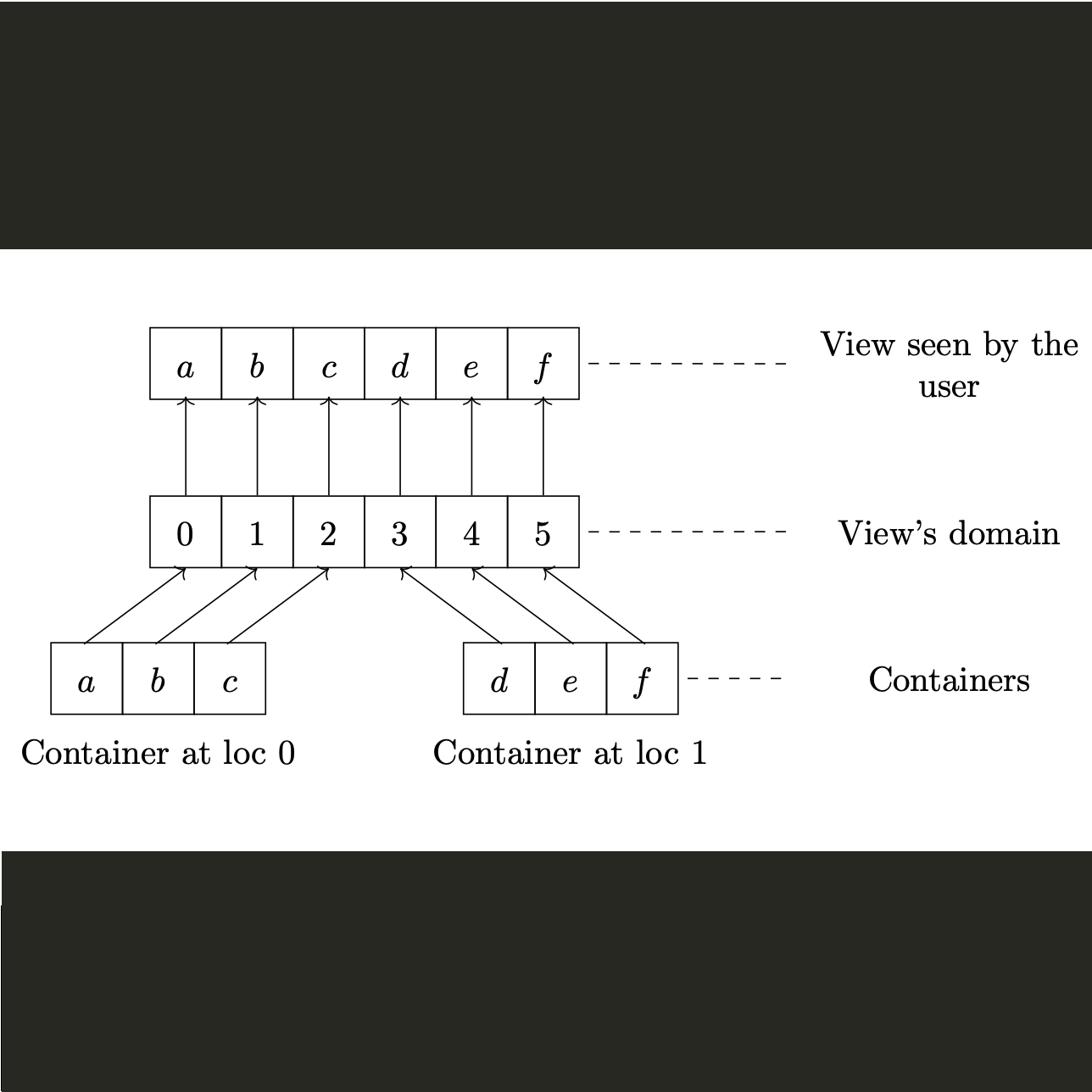
Parallel Program Composition with Paragraphs in Stapl, Timmie Smith, Doctoral dissertation, Parasol Laboratory, Department of Computer Science, Texas A&M University, College Station, TX, USA, Jan 2012.
Keywords: Parallel Libraries, Parallel Programming
Links : [Published]
BibTex
@phdthesis{CitekeyPhdthesis,
author = "Smith, Timmie",
title = "Parallel Program Composition with Paragraphs in Stapl",
school = "Texas A&M University",
address = "College Station, TX, USA",
year = 2012,
month = jan
}
Abstract
Languages and tools currently available for the development of parallel applications are difficult to learn and use. The Standard Template Adaptive Parallel Library (STAPL) is being developed to make it easier for programmers to implement a parallel application. STAPL is a parallel programming library for C++ that adopts the generic programming philosophy of the C++ Standard Template Library. STAPL provides collections of parallel algorithms (pAlgorithms) and containers (pContainers) that allow a developer to write their application without reimplementing the algorithms and data structures commonly used in parallel computing. pViews in STAPL are abstract data types that provide generic data access operations independently of the type of pContainer used to store the data. Algorithms and applications have a formal, high level representation in STAPL. A computation in STAPL is represented as a parallel task graph, which we call a PARAGRAPH. A PARAGRAPH contains a representation of the algorithm's input data, the operations that are used to transform individual data elements, and the ordering between the application of operations that transform the same data element. Just as programs are the result of a composition of algorithms, STAPL programs are the result of a composition of PARAGRAPHs. This dissertation develops the PARAGRAPH program representation and its compositional methods. PARAGRAPHs improve the developer's difficult situation by simplifying what she must specify when writing a parallel algorithm. The performance of the PARAGRAPH is evaluated using parallel generic algorithms, benchmarks from the NAS suite, and a nuclear particle transport application that has been written using STAPL. Our experiments were performed on Cray XT4 and Cray XE6 massively parallel systems and an IBM Power5 cluster, and show that scalable performance beyond 16,000 processors is possible using the PARAGRAPH.
The Paragraph: Design and Implementation of the STAPL Parallel Task Graph, Nathan Thomas, Doctoral dissertation, Parasol Laboratory, Department of Computer Science, Texas A&M University, College Station, TX, USA, Jan 2012.
Keywords: Parallel Libraries, Parallel Programming
Links : [Published]
BibTex
@phdthesis{CitekeyPhdthesis,
author = "Thomas, Nathan",
title = "Texas A&M University",
school = "College Station, TX, USA",
address = "Stanford, CA",
year = 2012,
month = jan
}
Abstract
Parallel programming is becoming mainstream due to the increased availability of multiprocessor and multicore architectures and the need to solve larger and more complex problems. Languages and tools available for the development of parallel applications are often difficult to learn and use. The Standard Template Adaptive Parallel Library (STAPL) is being developed to help programmers address these difficulties. STAPL is a parallel C++ library with functionality similar to STL, the ISO adopted C++ Standard Template Library. STAPL provides a collection of parallel pContainers for data storage and pViews that provide uniform data access operations by abstracting away the details of the pContainer data distribution. Generic pAlgorithms are written in terms of PARAGRAPHs, high level task graphs expressed as a composition of common parallel patterns. These task graphs define a set of operations on pViews as well as any ordering (i.e., dependences) on these operations that must be enforced by STAPL for a valid execution. The subject of this dissertation is the PARAGRAPH Executor, a framework that manages the runtime instantiation and execution of STAPL PARAGRAPHS. We address several challenges present when using a task graph program representation and discuss a novel approach to dependence specification which allows task graph creation and execution to proceed concurrently. This overlapping increases scalability and reduces the resources required by the PARAGRAPH Executor. We also describe the interface for task specification as well as optimizations that address issues such as data locality. We evaluate the performance of the PARAGRAPH Executor on several parallel machines including massively parallel Cray XT4 and Cray XE6 systems and an IBM Power5 cluster. Using tests including generic parallel algorithms, kernels from the NAS NPB suite, and a nuclear particle transport application written in STAPL, we demonstrate that the PARAGRAPH Executor enables STAPL to exhibit good scalability on more than $10^4$ processors.
From Days to Seconds: Scalable Parallel Algorithms for Motion Planning, Sam Ade Jacobs, Nancy M. Amato, In ACM Student Research Compet, Conf. on High Performance Computing Networking, Storage and Analysis Companion Proceedings, Seattle, Washington, USA, Nov 2011.
Keywords: Parallel Planning, Sampling-Based Motion Planning, STAPL
Links : [Published]
BibTex
N/A
Abstract
This work describes a scalable method for parallelizing sampling-based motion planning algorithms. It subdivides configuration space (C-space) into (possibly overlapping) regions and independently, in parallel, uses standard (sequential) sampling-based planners to construct roadmaps in each region. Next, in parallel, regional roadmaps in adjacent regions are connected to form a global roadmap. By subdividing the space and restricting the locality of connection attempts, we reduce the work and inter-processor communication associated with nearest neighbor calculation, a critical bottleneck for scalability in existing parallel motion planning methods.
We show that our method is general enough to handle a variety of planning schemes, including the widely used Probabilistic Roadmap (PRM) and Rapidly-exploring Random Trees (RRT) algorithms. We compare our approach to two other existing parallel algorithms and demonstrate that our approach achieves better and more scalable performance. Our approach achieves almost linear scalability on a 2400 core LINUX cluster and on a 153,216 core Cray XE6 petascale machine.
The STAPL Parallel Container Framework, Gabriel Tanase, Antal Buss, Adam Fidel, Harshvardhan, Ioannis Papadopoulos, Olga Pearce, Timmie Smith, Nathan Thomas, Xiabing Xu, Nedhal Mourad, Jeremy Vu, Mauro Bianco, Nancy M. Amato, Lawrence Rauchwerger, Proceedings of the 16th ACM Symposium on Principles and Practice of Parallel Programming (PPoPP), pp. 235-246, San Antonio, TX, USA, Feb 2011. DOI: 10.1145/1941553.1941586
Keywords: Parallel Containers, Parallel Programming, STAPL
Links : [Published]
BibTex
@article{10.1145/2038037.1941586,
author = {Tanase, Gabriel and Buss, Antal and Fidel, Adam and Harshvardhan and Papadopoulos, Ioannis and Pearce, Olga and Smith, Timmie and Thomas, Nathan and Xu, Xiabing and Mourad, Nedal and Vu, Jeremy and Bianco, Mauro and Amato, Nancy M. and Rauchwerger, Lawrence},
title = {The STAPL Parallel Container Framework},
year = {2011},
issue_date = {August 2011},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {46},
number = {8},
issn = {0362-1340},
url = {https://doi.org/10.1145/2038037.1941586},
doi = {10.1145/2038037.1941586},
abstract = {The Standard Template Adaptive Parallel Library (STAPL) is a parallel programming infrastructure that extends C++ with support for parallelism. It includes a collection of distributed data structures called pContainers that are thread-safe, concurrent objects, i.e., shared objects that provide parallel methods that can be invoked concurrently. In this work, we present the STAPL Parallel Container Framework (PCF), that is designed to facilitate the development of generic parallel containers. We introduce a set of concepts and a methodology for assembling a pContainer from existing sequential or parallel containers, without requiring the programmer to deal with concurrency or data distribution issues. The PCF provides a large number of basic parallel data structures (e.g., pArray, pList, pVector, pMatrix, pGraph, pMap, pSet). The PCF provides a class hierarchy and a composition mechanism that allows users to extend and customize the current container base for improved application expressivity and performance. We evaluate STAPL pContainer performance on a CRAY XT4 massively parallel system and show that pContainer methods, generic pAlgorithms, and different applications provide good scalability on more than 16,000 processors.},
journal = {SIGPLAN Not.},
month = feb,
pages = {235–246},
numpages = {12},
keywords = {languages, libraries, data, structures, containers, parallel}
}
@inproceedings{10.1145/1941553.1941586,
author = {Tanase, Gabriel and Buss, Antal and Fidel, Adam and Harshvardhan and Papadopoulos, Ioannis and Pearce, Olga and Smith, Timmie and Thomas, Nathan and Xu, Xiabing and Mourad, Nedal and Vu, Jeremy and Bianco, Mauro and Amato, Nancy M. and Rauchwerger, Lawrence},
title = {The STAPL Parallel Container Framework},
year = {2011},
isbn = {9781450301190},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/1941553.1941586},
doi = {10.1145/1941553.1941586},
abstract = {The Standard Template Adaptive Parallel Library (STAPL) is a parallel programming infrastructure that extends C++ with support for parallelism. It includes a collection of distributed data structures called pContainers that are thread-safe, concurrent objects, i.e., shared objects that provide parallel methods that can be invoked concurrently. In this work, we present the STAPL Parallel Container Framework (PCF), that is designed to facilitate the development of generic parallel containers. We introduce a set of concepts and a methodology for assembling a pContainer from existing sequential or parallel containers, without requiring the programmer to deal with concurrency or data distribution issues. The PCF provides a large number of basic parallel data structures (e.g., pArray, pList, pVector, pMatrix, pGraph, pMap, pSet). The PCF provides a class hierarchy and a composition mechanism that allows users to extend and customize the current container base for improved application expressivity and performance. We evaluate STAPL pContainer performance on a CRAY XT4 massively parallel system and show that pContainer methods, generic pAlgorithms, and different applications provide good scalability on more than 16,000 processors.},
booktitle = {Proceedings of the 16th ACM Symposium on Principles and Practice of Parallel Programming},
pages = {235–246},
numpages = {12},
keywords = {containers, libraries, structures, languages, parallel, data},
location = {San Antonio, TX, USA},
series = {PPoPP \'11}
}
Abstract
The Standard Template Adaptive Parallel Library (STAPL) is a parallel programming infrastructure that extends C++ with support for parallelism. It includes a collection of distributed data structures called pContainers that are thread-safe, concurrent objects, i.e., shared objects that provide parallel methods that can be invoked concurrently. In this work, we present the STAPL Parallel Container Framework (PCF), that is designed to facilitate the development of generic parallel containers. We introduce a set of concepts and a methodology for assembling a pContainer from existing sequential or parallel containers, without requiring the programmer to deal with concurrency or data distribution issues. The PCF provides a large number of basic parallel data structures (e.g., pArray, pList, pVector, pMatrix, pGraph, pMap, pSet). The PCF provides a class hierarchy and a composition mechanism that allows users to extend and customize the current container base for improved application expressivity and performance. We evaluate STAPL pContainer performance on a CRAY XT4 massively parallel system and show that pContainer methods, generic pAlgorithms, and different applications provide good scalability on more than 16,000 processors.
The STAPL pView, Antal Buss, Adam Fidel, Harshvardhan, Timmie Smith, Gabriel Tanase, Nathan Thomas, Xiabing Xu, Mauro Bianco, Nancy M. Amato, Lawrence Rauchwerger, Languages and Compilers for Parallel Computing (LCPC), pp. 261-275, Houston, Texas, USA, Oct 2010. DOI: 10.1007/978-3-642-19595-2_18
Keywords: Parallel Containers, Parallel Programming, STAPL
Links : [Published]
BibTex
@InProceedings{10.1007/978-3-642-19595-2_18,
author=\"Buss, Antal
and Fidel, Adam
and Harshvardhan
and Smith, Timmie
and Tanase, Gabriel
and Thomas, Nathan
and Xu, Xiabing
and Bianco, Mauro
and Amato, Nancy M.
and Rauchwerger, Lawrence\",
editor=\"Cooper, Keith
and Mellor-Crummey, John
and Sarkar, Vivek\",
title=\"The STAPL pView\",
booktitle=\"Languages and Compilers for Parallel Computing\",
year=\"2011\",
publisher=\"Springer Berlin Heidelberg\",
address=\"Berlin, Heidelberg\",
pages=\"261--275\",
abstract=\"The Standard Template Adaptive Parallel Library (STAPL) is a C++ parallel programming library that provides a collection of distributed data structures (pContainers) and parallel algorithms (pAlgorithms) and a generic methodology for extending them to provide customized functionality. STAPL algorithms are written in terms of pViews, which provide a generic access interface to pContainer data by abstracting common data structure concepts. Briefly, pViews allow the same pContainer to present multiple interfaces, e.g., enabling the same pMatrix to be `viewed\' (or used) as a row-major or column-major matrix, or even as a vector. In this paper, we describe the staplpView concept and its properties. pViews generalize the iterator concept and enable parallelism by providing random access to, and an ADT for, collections of elements. We illustrate how pViews provide support for managing the tradeoff between expressivity and performance and examine the performance overhead incurred when using pViews.\",
isbn=\"978-3-642-19595-2\"
}
Abstract
The Standard Template Adaptive Parallel Library (STAPL) is a C++ parallel programming library that provides a collection of distributed data structures (pContainers) and parallel algorithms (pAlgorithms) and a generic methodology for extending them to provide customized functionality. STAPL algorithms are written in terms of pViews, which provide a generic access interface to pContainer data by abstracting common data structure concepts. Briefly, pViews allow the same pContainer to present multiple interfaces, e.g., enabling the same pMatrix to be ÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂâÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂviewedÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂâÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂà(or used) as a row-major or column-major matrix, or even as a vector. In this paper, we describe the stapl pView concept and its properties. pViews generalize the iterator concept and enable parallelism by providing random access to, and an ADT for, collections of elements. We illustrate how pViews provide support for managing the tradeoff between expressivity and performance and examine the performance overhead incurred when using pViews.
STAPL: Standard Template Adaptive Parallel Library, Antal Buss, Harshvardhan, Ioannis Papadopoulos, Olga Tkachyshyn, Timmie Smith, Gabriel Tanase, Nathan Thomas, Xiabing Xu, Mauro Bianco, Nancy M. Amato, Lawrence Rauchwerger, Proceedings of the 3rd Annual Haifa Experimental Systems Conference, Haifa, Israel, May 2010. DOI: 10.1145/1815695.1815713
Keywords: High-Performance Computing, Parallel Programming, STAPL
Links : [Published]
BibTex
@inproceedings{10.1145/1815695.1815713,
author = {Buss, Antal and Harshvardhan and Papadopoulos, Ioannis and Pearce, Olga and Smith, Timmie and Tanase, Gabriel and Thomas, Nathan and Xu, Xiabing and Bianco, Mauro and Amato, Nancy M. and Rauchwerger, Lawrence},
title = {STAPL: Standard Template Adaptive Parallel Library},
year = {2010},
isbn = {9781605589084},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/1815695.1815713},
doi = {10.1145/1815695.1815713},
abstract = {The Standard Template Adaptive Parallel Library (stapl) is a high-productivity parallel programming framework that extends C++ and stl with unified support for shared and distributed memory parallelism. stapl provides distributed data structures (pContainers) and parallel algorithms (pAlgorithms) and a generic methodology for extending them to provide customized functionality. The stapl runtime system provides the abstraction for communication and program execution. In this paper, we describe the major components of stapl and present performance results for both algorithms and data structures showing scalability up to tens of thousands of processors.},
booktitle = {Proceedings of the 3rd Annual Haifa Experimental Systems Conference},
articleno = {14},
numpages = {10},
keywords = {high productivity parallel programming, parallel data structures, library},
location = {Haifa, Israel},
series = {SYSTOR \'10}
}
Abstract
The Standard Template Adaptive Parallel Library (stapl) is a high-productivity parallel programming framework that extends C++ and stl with unified support for shared and distributed memory parallelism. stapl provides distributed data structures (pContainers) and parallel algorithms (pAlgorithms) and a generic methodology for extending them to provide customized functionality. The stapl runtime system provides the abstraction for communication and program execution. In this paper, we describe the major components of stapl and present performance results for both algorithms and data structures showing scalability up to tens of thousands of processors.
The STAPL pList, Gabriel Tanase, Xiabing Xu, Antal Buss, Harshvardhan, Ioannis Papadopoulos, Olga Tkachyshyn, Timmie Smith, Nathan Thomas, Mauro Bianco, Nancy M. Amato, Lawrence Rauchwerger, Proceedings of the 22nd International Conference on Languages and Compilers for Parallel Computing, pp. 16-30, Newark, DE, USA, Oct 2009. DOI: 10.1007/978-3-642-13374-9_2
Keywords: Parallel Containers, Parallel Programming, STAPL
Links : [Published]
BibTex
@inproceedings{10.1007/978-3-642-13374-9_2,
author = {Tanase, Gabriel and Xu, Xiabing and Buss, Antal and Harshvardhan and Papadopoulos, Ioannis and Pearce, Olga and Smith, Timmie and Thomas, Nathan and Bianco, Mauro and Amato, Nancy M. and Rauchwerger, Lawrence},
title = {The STAPL Plist},
year = {2009},
isbn = {3642133738},
publisher = {Springer-Verlag},
address = {Berlin, Heidelberg},
url = {https://doi.org/10.1007/978-3-642-13374-9_2},
doi = {10.1007/978-3-642-13374-9_2},
abstract = {We present the design and implementation of the staplpList, a parallel container that has the properties of a sequential list, but allows for scalable concurrent access when used in a parallel program. The Standard Template Adaptive Parallel Library (stapl) is a parallel programming library that extends C++ with support for parallelism. stapl provides a collection of distributed data structures (pContainers) and parallel algorithms (pAlgorithms) and a generic methodology for extending them to provide customized functionality. staplpContainers are thread-safe, concurrent objects, providing appropriate interfaces (e.g., views) that can be used by generic pAlgorithms. The pList provides stl equivalent methods, such as insert, erase, and splice, additional methods such as split, and efficient asynchronous (non-blocking) variants of some methods for improved parallel performance. We evaluate the performance of the staplpList on an IBM Power 5 cluster and on a CRAY XT4 massively parallel processing system. Although lists are generally not considered good data structures for parallel processing, we show that pList methods and pAlgorithms (p_generate and p_partial_sum) operating on pLists provide good scalability on more than 103 processors and that pList compares favorably with other dynamic data structures such as the pVector.},
booktitle = {Proceedings of the 22nd International Conference on Languages and Compilers for Parallel Computing},
pages = {16–30},
numpages = {15},
location = {Newark, DE},
series = {LCPC\'09}
}
Abstract
We present the design and implementation of the staplpList, a parallel container that has the properties of a sequential list, but allows for scalable concurrent access when used in a parallel program. The Standard Template Adaptive Parallel Library (stapl) is a parallel programming library that extends C++ with support for parallelism. stapl provides a collection of distributed data structures (pContainers) and parallel algorithms (pAlgorithms) and a generic methodology for extending them to provide customized functionality. stapl pContainers are thread-safe, concurrent objects, providing appropriate interfaces (e.g., views) that can be used by generic pAlgorithms. The pList provides stl equivalent methods, such as insert, erase, and splice, additional methods such as split, and efficient asynchronous (non-blocking) variants of some methods for improved parallel performance. We evaluate the performance of the stapl pList on an IBM Power 5 cluster and on a CRAY XT4 massively parallel processing system. Although lists are generally not considered good data structures for parallel processing, we show that pList methods and pAlgorithms (p_generate and p_partial_sum) operating on pLists provide good scalability on more than 1000 processors and that pList compares favorably with other dynamic data structures such as the pVector.
Design for Interoperability in STAPL: pMatrices and Linear Algebra Algorithms, Antal Buss, Timmie Smith, Gabriel Tanase, Nathan Thomas, Mauro Bianco, Nancy M. Amato, Lawrence Rauchwerger, Languages and Compilers for Parallel Computing (LCPC 2008). Lecture Notes in Computer Science, vol 5335. Springer, pp. 304-315, Edmonton, Alberta, Canada, Jul 2008. DOI: 10.1007/978-3-540-89740-8_21
Keywords: Parallel Containers, Parallel Programming, STAPL
Links : [Published]
BibTex
@InProceedings{10.1007/978-3-540-89740-8_21,
author=\"Buss, Antal A.
and Smith, Timmie G.
and Tanase, Gabriel
and Thomas, Nathan L.
and Bianco, Mauro
and Amato, Nancy M.
and Rauchwerger, Lawrence\",
editor=\"Amaral, Jos{\\\'e} Nelson\",
title=\"Design for Interoperability in stapl: pMatrices and Linear Algebra Algorithms\",
booktitle=\"Languages and Compilers for Parallel Computing\",
year=\"2008\",
publisher=\"Springer Berlin Heidelberg\",
address=\"Berlin, Heidelberg\",
pages=\"304--315\",
abstract=\"The Standard Template Adaptive Parallel Library (stapl) is a high-productivity parallel programming framework that extends C++ and stl with unified support for shared and distributed memory parallelism. stapl provides distributed data structures (pContainers) and parallel algorithms (pAlgorithms) and a generic methodology for extending them to provide customized functionality. To improve productivity and performance, it is essential for stapl to exploit third party libraries, including those developed in programming languages other than C++. In this paper we describe a methodology that enables third party libraries to be used with stapl. This methodology allows a developer to specify when these specialized libraries can correctly be used, and provides mechanisms to transparently invoke them when appropriate. It also provides support for using staplpAlgorithms and pContainers in external codes. As a concrete example, we illustrate how third party libraries, namely BLAS and PBLAS, can be transparently embedded into stapl to provide efficient linear algebra algorithms for the staplpMatrix, with negligible slowdown with respect to the optimized libraries themselves.\",
isbn=\"978-3-540-89740-8\"
}
Abstract
The Standard Template Adaptive Parallel Library (stapl) is a high-productivity parallel programming framework that extends C++ and stl with unified support for shared and distributed memory parallelism. stapl provides distributed data structures (pContainers) and parallel algorithms (pAlgorithms) and a generic methodology for extending them to provide customized functionality. To improve productivity and performance, it is essential for stapl to exploit third party libraries, including those developed in programming languages other than C++. In this paper we describe a methodology that enables third party libraries to be used with stapl. This methodology allows a developer to specify when these specialized libraries can correctly be used, and provides mechanisms to transparently invoke them when appropriate. It also provides support for using stapl pAlgorithms and pContainers in external codes. As a concrete example, we illustrate how third party libraries, namely BLAS and PBLAS, can be transparently embedded into stapl to provide efficient linear algebra algorithms for the stapl pMatrix, with negligible slowdown with respect to the optimized libraries themselves.
Associative Parallel Containers In STAPL, Gabriel Tanase, Chidambareswaran (Chids) Raman, Mauro Bianco, Nancy M. Amato, Lawrence Rauchwerger, Languages and Compilers for Parallel Computing (LCPC), pp. 156-171, Urbana, IL, USA, Oct 2007. DOI: 10.1007/978-3-540-85261-2_11
Keywords: Parallel Containers, Parallel Programming, STAPL
Links : [Published]
BibTex
@InProceedings{10.1007/978-3-540-85261-2_11,
author=\"Tanase, Gabriel
and Raman, Chidambareswaran
and Bianco, Mauro
and Amato, Nancy M.
and Rauchwerger, Lawrence\",
editor=\"Adve, Vikram
and Garzar{\\\'a}n, Mar{\\\'i}a Jes{\\\'u}s
and Petersen, Paul\",
title=\"Associative Parallel Containers in STAPL\",
booktitle=\"Languages and Compilers for Parallel Computing\",
year=\"2008\",
publisher=\"Springer Berlin Heidelberg\",
address=\"Berlin, Heidelberg\",
pages=\"156--171\",
abstract=\"The Standard Template Adaptive Parallel Library (stapl) is a parallel programming framework that extends C++ and stl with support for parallelism. stapl provides a collection of parallel data structures (pContainers) and algorithms (pAlgorithms) and a generic methodology for extending them to provide customized functionality. staplpContainers are thread-safe, concurrent objects, i.e., shared objects that provide parallel methods that can be invoked concurrently. They also provide appropriate interfaces that can be used by generic pAlgorithms. In this work, we present the design and implementation of the stapl associative pContainers: pMap, pSet, pMultiMap, pMultiSet, pHashMap, and pHashSet. These containers provide optimal insert, search, and delete operations for a distributed collection of elements based on keys. Their methods include counterparts of the methods provided by the stl associative containers, and also some asynchronous (non-blocking) variants that can provide improved performance in parallel. We evaluate the performance of the stapl associative pContainers on an IBM Power5 cluster, an IBM Power3 cluster, and on a linux-based Opteron cluster, and show that the new pContainer asynchronous methods, generic pAlgorithms (e.g., pfind) and a sort application based on associative pContainers, all provide good scalability on more than 1000 processors.\",
isbn=\"978-3-540-85261-2\"
}
Abstract
The Standard Template Adaptive Parallel Library (stapl) is a parallel programming framework that extends C++ and stl with support for parallelism. stapl provides a collection of parallel data structures (pContainers) and algorithms (pAlgorithms) and a generic methodology for extending them to provide customized functionality. stapl pContainers are thread-safe, concurrent objects, i.e., shared objects that provide parallel methods that can be invoked concurrently. They also provide appropriate interfaces that can be used by generic pAlgorithms. In this work, we present the design and implementation of the stapl associative pContainers: pMap, pSet, pMultiMap, pMultiSet, pHashMap, and pHashSet. These containers provide optimal insert, search, and delete operations for a distributed collection of elements based on keys. Their methods include counterparts of the methods provided by the stl associative containers, and also some asynchronous (non-blocking) variants that can provide improved performance in parallel. We evaluate the performance of the stapl associative pContainers on an IBM Power5 cluster, an IBM Power3 cluster, and on a linux-based Opteron cluster, and show that the new pContainer asynchronous methods, generic pAlgorithms (e.g., pfind) and a sort application based on associative pContainers, all provide good scalability on more than 1000 processors.
The STAPL pArray, Gabriel Tanase, Mauro Bianco, Nancy M. Amato, Lawrence Rauchwerger, Proceedings of the 2007 Workshop on MEmory Performance: DEaling with Applications, Systems and Architecture (MEDEA), pp. 73-80, Brasov, Romania, Sep 2007. DOI: 10.1145/1327171.1327180
Keywords: Parallel Containers, Parallel Programming, STAPL
Links : [Published]
BibTex
@inproceedings{10.1145/1327171.1327180,
author = {Tanase, Gabriel and Bianco, Mauro and Amato, Nancy M. and Rauchwerger, Lawrence},
title = {The STAPL PArray},
year = {2007},
isbn = {9781595938077},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/1327171.1327180},
doi = {10.1145/1327171.1327180},
abstract = {The Standard Template Adaptive Parallel Library (STAPL) is a parallel programming framework that extends C++ and STL with support for parallelism. STAPL provides parallel data structures (pContainers) and generic parallel algorithms (pAlgorithms), and a methodology for extending them to provide customized functionality. STAPL pContainers are thread-safe, concurrent objects, i.e., shared objects that provide parallel methods that can be invoked concurrently. They provide views as a generic means to access data that can be passed as input to generic pAlgorithms.In this work, we present the STAPL pArray, the parallel equivalent of the sequential STL valarray, a fixed-size data structure optimized for storing and accessing data based on one-dimensional indices. We describe the pArray design and show how it can support a variety of underlying data distribution policies currently available in STAPL, such as blocked or blocked cyclic. We provide experimental results showing that pAlgorithms using the pArray scale well to more than 2,000 processors. We also provide results using different data distributions that illustrate that the performance of pAlgorithms and pArray methods is usually sensitive to the underlying data distribution, and moreover, that there is no one data distribution that performs best for all pAlgorithms, processor counts, or machines.},
booktitle = {Proceedings of the 2007 Workshop on MEmory Performance: DEaling with Applications, Systems and Architecture},
pages = {73–80},
numpages = {8},
location = {Brasov, Romania},
series = {MEDEA \'07}
}
Abstract
The Standard Template Adaptive Parallel Library (STAPL) is a parallel programming framework that extends C++ and STL with support for parallelism. STAPL provides parallel data structures (pContainers) and generic parallel algorithms (pAlgorithms), and a methodology for extending them to provide customized functionality. STAPL pContainers are thread-safe, concurrent objects, i.e., shared objects that provide parallel methods that can be invoked concurrently. They provide views as a generic means to access data that can be passed as input to generic pAlgorithms.
In this work, we present the STAPL pArray, the parallel equivalent of the sequential STL valarray, a fixed-size data structure optimized for storing and accessing data based on one-dimensional indices. We describe the pArray design and show how it can support a variety of underlying data distribution policies currently available in STAPL, such as blocked or blocked cyclic. We provide experimental results showing that pAlgorithms using the pArray scale well to more than 2,000 processors. We also provide results using different data distributions that illustrate that the performance of pAlgorithms and pArray methods is usually sensitive to the underlying data distribution, and moreover, that there is no one data distribution that performs best for all pAlgorithms, processor counts, or machines.
Custom Memory Allocation for Free: Improving Data Locality with Container-Centric Memory Allocation, Alin Jula, Lawrence Rauchwerger, Languages and Compilers for Parallel Computing (LCPC.) Lecture Notes in Computer Science, Vol: 4382, New Orleans, Louisiana, USA, Nov 2006. DOI: 10.1007/978-3-540-72521-3_22
Keywords: Memory Management, Runtime Systems, STAPL
Links : [Published]
BibTex
@InProceedings{10.1007/978-3-540-72521-3_22,
author="Jula, Alin
and Rauchwerger, Lawrence",
editor="Alm{\'a}si, George
and Ca{\c{s}}caval, C{\u{a}}lin
and Wu, Peng",
title="Custom Memory Allocation for Free",
booktitle="Languages and Compilers for Parallel Computing",
year="2007",
publisher="Springer Berlin Heidelberg",
address="Berlin, Heidelberg",
pages="299--313",
abstract="We present a novel and efficient container-centric memory allocator, named Defero, which allows a container to guide the allocation of its elements. The guidance is supported by the semantic-rich context of containers in which a new element is inserted. Defero allocates based on two attributes: size and location. Our policy of allocating a new object close to a related object often results in significantly increased memory reference locality. Defero has been integrated to work seamlessly with the C++ Standard Template Library (STL) containers. The communication between containers and the memory allocator is very simple and insures portability. STL container modification is the only needed code change to achieve custom memory allocation. We present experimental results that show the performance improvements that can be obtained by using Defero as a custom allocator for STL applications. We have applied our memory allocator to the molecular dynamics and compiler applications and obtained significant performance improvements over using the standard GNU STL allocator. With our approach custom memory allocation has been achieved without any modification of the actual applications, i.e., without additional programming efforts.",
isbn="978-3-540-72521-3"
}
Abstract
We present a novel and efficient container-centric memory allocator, named Defero, which allows a container to guide the allocation of its elements. The guidance is supported by the semantic-rich context of containers in which a new element is inserted. Defero allocates based on two attributes: size and location. Our policy of allocating a new object close to a related object often results in significantly increased memory reference locality. Defero has been integrated to work seamlessly with the C++ Standard Template Library (STL) containers. The communication between containers and the memory allocator is very simple and insures portability. STL container modification is the only needed code change to achieve custom memory allocation. We present experimental results that show the performance improvements that can be obtained by using Defero as a custom allocator for STL applications. We have applied our memory allocator to the molecular dynamics and compiler applications and obtained significant performance improvements over using the standard GNU STL allocator. With our approach custom memory allocation has been achieved without any modification of the actual applications, i.e., without additional programming efforts.
ARMI: A High Level Communication Library for STAPL, Nathan Thomas, Steven Saunders, Tim Smith, Gabriel Tanase, Lawrence Rauchwerger, Parallel Processing Letters, Vol: 16, Issue: 2, pp. 261-280, Jun 2006. DOI: 10.1142/S0129626406002617
Keywords: Communication Library, Remote Method Invocation, Runtime Systems
Links : [Published]
BibTex
@article{10.1142/S0129626406002617,
author = "Nathan Thomas and Steven Saunders and Tim Smith and Gabriel Tanase and Lawrence Rauchwerger",
title = "ARMI: A High Level Communication Library for STAPL",
journal = "Parallel Processing Letters",
year = 2006,
volume = "16",
number = "2",
pages = "261-280",
}
Abstract
ARMI is a communication library that provides a framework for expressing fine-grain parallelism and mapping it to a particular machine using shared-memory and message passing library calls. The library is an advanced implementation of the RMI protocol and handles low-level details such as scheduling incoming communication and aggregating outgoing communication to coarsen parallelism. These details can be tuned for different platforms to allow user codes to achieve the highest performance possible without manual modification. ARMI is used by STAPL, our generic parallel library, to provide a portable, user transparent communication layer. We present the basic design as well as the mechanisms used in the current Pthreads/OpenMP, MPI implementations and/or a combination thereof. Performance comparisons between ARMI and explicit use of Pthreads or MPI are given on a variety of machines, including an HP-V2200, Origin 3800, IBM Regatta and IBM RS/6000 SP cluster.
Parallel Protein Folding with STAPL, Shawna Thomas, Gabriel Tanase, Lucia K. Dale, Jose E. Moreira, Lawrence Rauchwerger, Nancy M. Amato, Concurrency and Computation: Practice and Experience, Vol: 17, Issue: 14, pp. 1643-1656, Dec 2005. DOI: https://doi.org/10.1002/cpe.950
Keywords: Parallel Planning, Protein Folding, STAPL
Links : [Published]
BibTex
@article{https://doi.org/10.1002/cpe.950,
author = {Thomas, Shawna and Tanase, Gabriel and Dale, Lucia K. and Moreira, Jose M. and Rauchwerger, Lawrence and Amato, Nancy M.},
title = {Parallel protein folding with STAPL},
journal = {Concurrency and Computation: Practice and Experience},
volume = {17},
number = {14},
pages = {1643-1656},
keywords = {protein folding, motion planning, parallel libraries, C++},
doi = {https://doi.org/10.1002/cpe.950},
url = {https://onlinelibrary.wiley.com/doi/abs/10.1002/cpe.950},
eprint = {https://onlinelibrary.wiley.com/doi/pdf/10.1002/cpe.950},
abstract = {Abstract The protein-folding problem is a study of how a protein dynamically folds to its so-called native state—an energetically stable, three-dimensional conformation. Understanding this process is of great practical importance since some devastating diseases such as Alzheimer's and bovine spongiform encephalopathy (Mad Cow) are associated with the misfolding of proteins. We have developed a new computational technique for studying protein folding that is based on probabilistic roadmap methods for motion planning. Our technique yields an approximate map of a protein's potential energy landscape that contains thousands of feasible folding pathways. We have validated our method against known experimental results. Other simulation techniques, such as molecular dynamics or Monte Carlo methods, require many orders of magnitude more time to produce a single, partial trajectory. In this paper we report on our experiences parallelizing our method using STAPL (Standard Template Adaptive Parallel Library) that is being developed in the Parasol Lab at Texas A\&M. An efficient parallel version will enable us to study larger proteins with increased accuracy. We demonstrate how STAPL enables portable efficiency across multiple platforms, ranging from small Linux clusters to massively parallel machines such as IBM's BlueGene/L, without user code modification. Copyright © 2005 John Wiley \& Sons, Ltd.},
year = {2005}
}
Abstract
The protein-folding problem is a study of how a protein dynamically folds to its so-called native state - an energetically stable, three-dimensional conformation. Understanding this process is of great practical importance since some devastating diseases such as Alzheimer's and bovine spongiform encephalopathy (Mad Cow) are associated with the misfolding of proteins. We have developed a new computational technique for studying protein folding that is based on probabilistic roadmap methods for motion planning. Our technique yields an approximate map of a protein's potential energy landscape that contains thousands of feasible folding pathways. We have validated our method against known experimental results. Other simulation techniques, such as molecular dynamics or Monte Carlo methods, require many orders of magnitude more time to produce a single, partial trajectory. In this paper we report on our experiences parallelizing our method using STAPL (Standard Template Adaptive Parallel Library) that is being developed in the Parasol Lab at Texas A&M. An efficient parallel version will enable us to study larger proteins with increased accuracy. We demonstrate how STAPL enables portable efficiency across multiple platforms, ranging from small Linux clusters to massively parallel machines such as IBM's BlueGene/L, without user code modification.
A Framework for Adaptive Algorithm Selection in STAPL, Nathan Thomas, Gabriel Tanase, Olga Tkachyshyn, Jack Perdue, Nancy M. Amato, Lawrence Rauchwerger, Proceedings of the Tenth ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP), pp. 277-288, Chicago, IL, USA, Jun 2005. DOI: 10.1145/1065944.1065981
Keywords: Parallel Algorithms, Parallel Programming, STAPL
Links : [Published]
BibTex
@inproceedings{10.1145/1065944.1065981,
author = {Thomas, Nathan and Tanase, Gabriel and Tkachyshyn, Olga and Perdue, Jack and Amato, Nancy M. and Rauchwerger, Lawrence},
title = {A Framework for Adaptive Algorithm Selection in STAPL},
year = {2005},
isbn = {1595930809},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/1065944.1065981},
doi = {10.1145/1065944.1065981},
abstract = {Writing portable programs that perform well on multiple platforms or for varying input sizes and types can be very difficult because performance is often sensitive to the system architecture, the run-time environment, and input data characteristics. This is even more challenging on parallel and distributed systems due to the wide variety of system architectures. One way to address this problem is to adaptively select the best parallel algorithm for the current input data and system from a set of functionally equivalent algorithmic options. Toward this goal, we have developed a general framework for adaptive algorithm selection for use in the Standard Template Adaptive Parallel Library (STAPL). Our framework uses machine learning techniques to analyze data collected by STAPL installation benchmarks and to determine tests that will select among algorithmic options at run-time. We apply a prototype implementation of our framework to two important parallel operations, sorting and matrix multiplication, on multiple platforms and show that the framework determines run-time tests that correctly select the best performing algorithm from among several competing algorithmic options in 86-100% of the cases studied, depending on the operation and the system.},
booktitle = {Proceedings of the Tenth ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming},
pages = {277–288},
numpages = {12},
keywords = {machine learning, parallel algorithms, matrix multiplication, sorting, adaptive algorithms},
location = {Chicago, IL, USA},
series = {PPoPP \'05}
}
Abstract
Writing portable programs that perform well on multiple platforms or for varying input sizes and types can be very difficult because performance is often sensitive to the system architecture, the run-time environment, and input data characteristics. This is even more challenging on parallel and distributed systems due to the wide variety of system architectures. One way to address this problem is to adaptively select the best parallel algorithm for the current input data and system from a set of functionally equivalent algorithmic options. Toward this goal, we have developed a general framework for adaptive algorithm selection for use in the Standard Template Adaptive Parallel Library (STAPL). Our framework uses machine learning techniques to analyze data collected by STAPL installation benchmarks and to determine tests that will select among algorithmic options at run-time. We apply a prototype implementation of our framework to two important parallel operations, sorting and matrix multiplication, on multiple platforms and show that the framework determines run-time tests that correctly select the best performing algorithm from among several competing algorithmic options in 86-100% of the cases studied, depending on the operation and the system.
Parallel Protein Folding with STAPL, Shawna Thomas, Nancy M. Amato, 18th International Parallel and Distributed Processing Symposium (IPDPS), pp. 189-, Santa Fe, NM, USA, Apr 2004. DOI: 10.1109/IPDPS.2004.1303204
Keywords: Parallel Planning, Protein Folding, STAPL
Links : [Published]
BibTex
@INPROCEEDINGS{1303204,
author={S. {Thomas} and N. M. {Amato}},
booktitle={18th International Parallel and Distributed Processing Symposium, 2004. Proceedings.},
title={Parallel protein folding with STAPL},
year={2004},
volume={},
number={},
pages={189-},
doi={10.1109/IPDPS.2004.1303204}}
Abstract
Summary form only given. The protein folding problem is to study how a protein dynamically folds to its so-called native state - an energetically stable, three-dimensional configuration. Understanding this process is of great practical importance since some devastating diseases such as Alzheimer\'s and bovine spongiform encephalopathy (Mad Cow) are associated with the misfolding of proteins. In our group, we have developed a new computational technique for studying protein folding that is based on probabilistic roadmap methods for motion planning. Our technique yields an approximate map of a protein\'s potential energy landscape that contains thousands of feasible folding pathways. We have validated our method against known experimental results. Other simulation techniques, such as molecular dynamics or Monte Carlo methods, require many orders of magnitude more time to produce a single, partial, trajectory. We report on our experiences parallelizing our method using STAPL (the standard template adaptive parallel library), that is being developed in the Parasol Lab at Texas A&M. An efficient parallel version enables us to study larger proteins with increased accuracy. We demonstrate how STAPL enables portable efficiency across multiple platforms without user code modification. We show performance gains on two systems: a dedicated Linux cluster and an extremely heterogeneous multiuser Linux cluster.
ARMI: An Adaptive, Platform Independent Communication Library, Steven Saunders, Lawrence Rauchwerger, Proceedings of the Ninth ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP), pp. 230-241, San Diego, California, USA, Jun 2003. DOI: 10.1145/781498.781534
Keywords: Communication Library, Remote Method Invocation, STAPL
Links : [Published]
BibTex
@inproceedings{10.1145/781498.781534,
author = {Saunders, Steven and Rauchwerger, Lawrence},
title = {ARMI: An Adaptive, Platform Independent Communication Library},
year = {2003},
isbn = {1581135882},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/781498.781534},
doi = {10.1145/781498.781534},
abstract = {ARMI is a communication library that provides a framework for expressing fine-grain parallelism and mapping it to a particular machine using shared-memory and message passing library calls. The library is an advanced implementation of the RMI protocol and handles low-level details such as scheduling incoming communication and aggregating outgoing communication to coarsen parallelism when necessary. These details can be tuned for different platforms to allow user codes to achieve the highest performance possible without manual modification. ARMI is used by STAPL, our generic parallel library, to provide a portable, user transparent communication layer. We present the basic design as well as the mechanisms used in the current Pthreads/OpenMP, MPI implementations and/or a combination thereof. Performance comparisons between ARMI and explicit use of Pthreads or MPI are given on a variety of machines, including an HP V2200, SGI Origin 3800, IBM Regatta-HPC and IBM RS6000 SP cluster.},
booktitle = {Proceedings of the Ninth ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming},
pages = {230–241},
numpages = {12},
keywords = {MPI, parallel programming, RPC, Pthreads, communication library, OpenMP, run-time system, RMI},
location = {San Diego, California, USA},
series = {PPoPP \'03}
}
@article{10.1145/966049.781534,
author = {Saunders, Steven and Rauchwerger, Lawrence},
title = {ARMI: An Adaptive, Platform Independent Communication Library},
year = {2003},
issue_date = {October 2003},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {38},
number = {10},
issn = {0362-1340},
url = {https://doi.org/10.1145/966049.781534},
doi = {10.1145/966049.781534},
abstract = {ARMI is a communication library that provides a framework for expressing fine-grain parallelism and mapping it to a particular machine using shared-memory and message passing library calls. The library is an advanced implementation of the RMI protocol and handles low-level details such as scheduling incoming communication and aggregating outgoing communication to coarsen parallelism when necessary. These details can be tuned for different platforms to allow user codes to achieve the highest performance possible without manual modification. ARMI is used by STAPL, our generic parallel library, to provide a portable, user transparent communication layer. We present the basic design as well as the mechanisms used in the current Pthreads/OpenMP, MPI implementations and/or a combination thereof. Performance comparisons between ARMI and explicit use of Pthreads or MPI are given on a variety of machines, including an HP V2200, SGI Origin 3800, IBM Regatta-HPC and IBM RS6000 SP cluster.},
journal = {SIGPLAN Not.},
month = jun,
pages = {230–241},
numpages = {12},
keywords = {RPC, RMI, Pthreads, run-time system, OpenMP, parallel programming, MPI, communication library}
}
Abstract
ARMI is a communication library that provides a framework for expressing fine-grain parallelism and mapping it to a particular machine using shared-memory and message passing library calls. The library is an advanced implementation of the RMI protocol and handles low-level details such as scheduling incoming communication and aggregating outgoing communication to coarsen parallelism when necessary. These details can be tuned for different platforms to allow user codes to achieve the highest performance possible without manual modification. ARMI is used by STAPL, our generic parallel library, to provide a portable, user transparent communication layer. We present the basic design as well as the mechanisms used in the current Pthreads/OpenMP, MPI implementations and/or a combination thereof. Performance comparisons between ARMI and explicit use of Pthreads or MPI are given on a variety of machines, including an HP V2200, SGI Origin 3800, IBM Regatta-HPC and IBM RS6000 SP cluster.
Object Oriented Abstractions for Communication in Parallel Programs, Steven Saunders, Masters Thesis, Parasol Laboratory, Department of Computer Science, Texas A&M University, College Station, TX, USA, May 2003.
Keywords: Communication Library, Runtime Systems, STAPL
Links : [Published]
BibTex
N/A
Abstract
This thesis details ARMI, a parallel communication library that provides an advanced implementation of the remote method invocation protocol (RMI), which is well suited to object-oriented programs. ARMI is a framework for expressing fine-grain parallelism in C++, and mapping it to a particular machine using shared-memory and message passing library calls. It handles low-level details such as scheduling incoming communication and aggregating outgoing communication to coarsen parallelism when necessary. These details can be adapted for different platforms to allow user codes to achieve the highest possible performance without manual modification. ARMI is used by STAPL, a generic, object-oriented, parallel C++ library, to provide a portable communication infrastructure. The basic design decisions are described, as well as a detailed analysis of the mechanisms used in the current OpenMP/Pthreads, MPI, and mixed-mode implementations. ARMIÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂâÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂÃÂs performance is compared with both hand-coded Pthreads and MPI on a variety of machines, including an HP-V2200, Origin 3800, IBM Regatta and IBM RS6000 SP.
A parallel communication infrastructure for STAPL, Steven Saunders, Lawrence Rauchwerger, Workshop on Performance Optimization for High-Level Languages and Libraries (POHLL), New York, NY, USA, Jun 2002.
Keywords: Communication Library, Runtime Systems, STAPL
Links : [Published] [Talk]
BibTex
N/A
Abstract
Communication is an important but difficult aspect of parallel programming. This paper describes a parallel communication infrastructure, based on remote method invocation, to simplify parallel programming by abstracting lowlevel shared-memory or message passing details while maintaining high performance and portability. STAPL, the Standard Template Adaptive Parallel Library, builds upon this infrastructure to make communication transparent to the user. The basic design is discussed, as well as the mechanisms used in the current Pthreads and MPI implementations. Performance comparisons between STAPL and explicit Pthreads or MPI are given on a variety of machines, including an HPV2200, Origin 3800 and a Linux Cluster.
STAPL: An Adaptive, Generic Parallel C++ Library, Ping An, Alin Jula, Silvius Rus, Steven Saunders, Tim Smith, Gabriel Tanase, Nathan Thomas, Nancy Amato, Lawrence Rauchwerger, Languages and Compilers for Parallel Computing (LCPC.) Lecture Notes in Computer Science, Vol: 2624, pp. 193-208, Cumberland Falls, KY, USA, Aug 2001. DOI: 10.1007/3-540-35767-X_13
Keywords: High-Performance Computing, Parallel Programming, STAPL
Links : [Published]
BibTex
@InProceedings{10.1007/3-540-35767-X_13,
author="An, Ping
and Jula, Alin
and Rus, Silvius
and Saunders, Steven
and Smith, Tim
and Tanase, Gabriel
and Thomas, Nathan
and Amato, Nancy
and Rauchwerger, Lawrence",
editor="Dietz, Henry G.",
title="STAPL: An Adaptive, Generic Parallel C++ Library",
booktitle="Languages and Compilers for Parallel Computing",
year="2003",
publisher="Springer Berlin Heidelberg",
address="Berlin, Heidelberg",
pages="193--208",
abstract="The Standard Template Adaptive Parallel Library (STAPL) is a parallel library designed as a superset of the ANSI C++ Standard Template Library (STL). It is sequentially consistent for functions with the same name, and executes on uni- or multi-processor systems that utilize shared or distributed memory. STAPL is implemented using simple parallel extensions of C++ that currently provide a SPMD model of parallelism, and supports nested parallelism. The library is intended to be general purpose, but emphasizes irregular programs to allow the exploitation of parallelism for applications which use dynamically linked data structures such as particle transport calculations, molecular dynamics, geometric modeling, and graph algorithms. STAPL provides several different algorithms for some library routines, and selects among them adaptively at runtime. STAPL can replace STL automatically by invoking a preprocessing translation phase. In the applications studied, the performance of translated code was within 5{\%} of the results obtained using STAPL directly. STAPL also provides functionality to allow the user to further optimize the code and achieve additional performance gains. We present results obtained using STAPL for a molecular dynamics code and a particle transport code.",
isbn="978-3-540-35767-4"
}
Abstract
The Standard Template Adaptive Parallel Library (STAPL) is a parallel library designed as a superset of the ANSI C++ Standard Template Library (STL). It is sequentially consistent for functions with the same name, and executes on uni- or multi-processor systems that utilize shared or distributed memory. STAPL is implemented using simple parallel extensions of C++ that currently provide a SPMD model of parallelism, and supports nested parallelism. The library is intended to be general purpose, but emphasizes irregular programs to allow the exploitation of parallelism for applications which use dynamically linked data structures such as particle transport calculations, molecular dynamics, geometric modeling, and graph algorithms. STAPL provides several different algorithms for some library routines, and selects among them adaptively at runtime. STAPL can replace STL automatically by invoking a preprocessing translation phase. In the applications studied, the performance of translated code was within 5% of the results obtained using STAPL directly. STAPL also provides functionality to allow the user to further optimize the code and achieve additional performance gains. We present results obtained using STAPL for a molecular dynamics code and a particle transport code.
STAPL: A standard template adaptive parallel C++ library, Ping An, Alin Jula, Silvius Rus, Steven Saunders, Tim Smith, Gabriel Tanase, Nathan Thomas, Nancy Amato, Lawrence Rauchwerger, Int. Wkshp on Adv. Compiler Technology for High Perf. and Embedded Processors, pp. 10-, Bucharest, Romania, Jul 2001.
Keywords: C++, Parallel Libraries, STAPL
Links : [Published]
BibTex
@INPROCEEDINGS{An01stapl:a,
author = {Ping An and Alin Jula and Silvius Rus and Steven Saunders and Tim Smith and Gabriel Tanase and Nathan Thomas Nancy M. Amato},
title = {STAPL: A standard template adaptive parallel C++ library},
booktitle = {In Int. Wkshp on Adv. Compiler Technology for High Perf. and Embedded Processors},
year = {2001},
pages = {10}
}
Abstract
The Standard Template Adaptive Parallel Library (STAPL) is a parallel library designed as a superset of the ANSI C++ Standard Template Library (STL). It is sequentially consistent for functions with the same name, and executes on uni-or multi-processor systems that utilize shared or distributed memory. STAPL is implemented using simple parallel extensions of C++ that currently provide a SPMD model of parallelism, and supports nested parallelism. The library is intended to be general purpose, but emphasizes irregular programs to allow the exploitation of parallelism in areas such as particle transport calculations, molecular dynamics, geometric modeling, and graph algorithms, which use dynamically linked data structures. STAPL provides several different algorithms for some library routines, and selects among them adaptively at run-time. STAPL can replace STL automatically by invoking a preprocessing translation phase. The performance of translated code is close to the results obtained using STAPL directly (less than 5% performance deterioration). However, STAPL also provides functionality to allow the user to further optimize the code and achieve additional performance gains. We present results obtained using STAPL for a molecular dynamics code and a particle transport code.
Standard Templates Adaptive Parallel Library (STAPL), Lawrence Rauchwerger, Francisco Arzu, K Ouchi, Languages, Compilers, and Run-Time Systems for Scalable Computers, pp. 402-409, Pittsburgh, PA, USA, May 1998. DOI: 10.1007/3-540-49530-4_32
Keywords: High-Performance Computing, Parallel Programming, STAPL
Links : [Published]
BibTex
@InProceedings{10.1007/3-540-49530-4_32,
author=\"Rauchwerger, Lawrence
and Arzu, Francisco
and Ouchi, Koji\",
editor=\"O\'Hallaron, David R.\",
title=\"Standard Templates Adaptive Parallel Library (STAPL)\",
booktitle=\"Languages, Compilers, and Run-Time Systems for Scalable Computers\",
year=\"1998\",
publisher=\"Springer Berlin Heidelberg\",
address=\"Berlin, Heidelberg\",
pages=\"402--409\",
abstract=\"STAPL (Standard Adaptive Parallel Library) is a parallel C++ library designed as a superset of the STL, sequentially consistent for functions with the same name, and executes on uni- or multiprocessors. STAPL is implemented using simple parallel extensions of C++ which provide a SPMD model of parallelism supporting recursive parallelism. The library is intended to be of generic use but emphasizes irregular, non-numeric programs to allow the exploitation of parallelism in areas such as geometric modeling or graph algorithms which use dynamic linked data structures. Each library routine has several dicfferent algorithmic options, and the choice among them will be made adaptively based on a performance model, statistical feedback, and current run-time conditions. Builtc-in performance monitors can measure actual performance and, using an extension of the BSP model predict the relative performance of the algorithmic choices for each library routine. STAPL is intended to possibly replace STL in a user transparent manner and run on small to medium scale shared memory multiprocessors which support OpenMP.\",
isbn=\"978-3-540-49530-7\"
}
Abstract
STAPL (Standard Adaptive Parallel Library) is a parallel C++ library designed as a superset of the STL, sequentially consistent for functions with the same name, and executes on uni- or multiprocessors. STAPL is implemented using simple parallel extensions of C++ which provide a SPMD model of parallelism supporting recursive parallelism. The library is intended to be of generic use but emphasizes irregular, non-numeric programs to allow the exploitation of parallelism in areas such as geometric modeling or graph algorithms which use dynamic linked data structures. Each library routine has several different algorithmic options, and the choice among them will be made adaptively based on a performance model, statistical feedback, and current run-time conditions. Built-in performance monitors can measure actual performance and, using an extension of the BSP model predict the relative performance of the algorithmic choices for each library routine. STAPL is intended to possibly replace STL in a user transparent manner and run on small to medium scale shared memory multiprocessors which support OpenMP.